你将会了解到以下几个知识点
- ISR什么时候收缩
- ISR什么时候扩展
- ISR的传播机制
- Broker宕机之后怎么ISR的收缩?
Kafka在启动的时候,会启动一个副本管理器ReplicaManager,这个副本管理器会启动几个定时任务。
ISR过期定时任务isr-expiration,每隔replica.lag.time.max.ms/2毫秒就执行一次。
ISR变更的传播定时任务isr-change-propagation,每隔2500毫秒就执行一次。
replica.lag.time.max.ms : 如果一个follower在这个时间内没有发送fetch请求,leader将从ISR中移除这个follower。从2.5开始 ,默认值从 10 秒增加到 30 秒。
接下来我们分析一下这两个定时任务的作用。
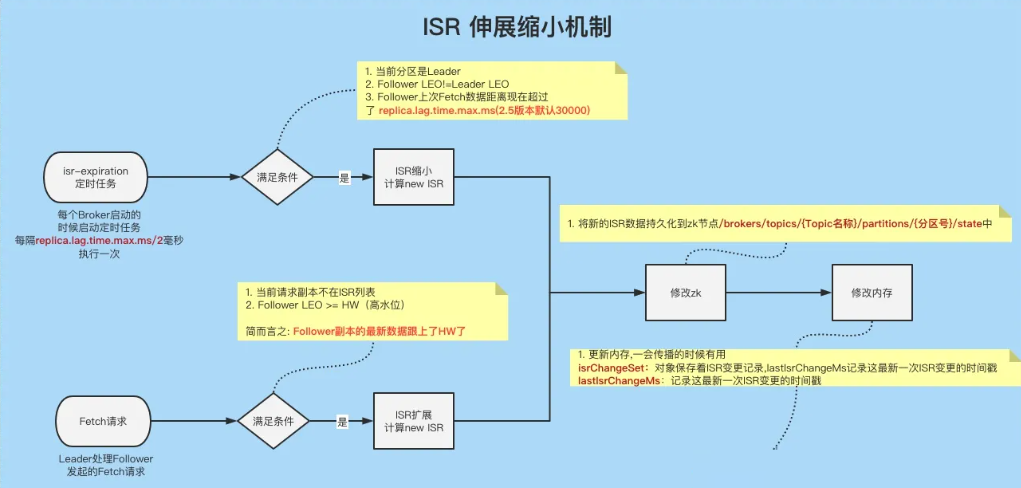
ISR收缩 isr-expiration
每隔replica.lag.time.max.ms/2毫秒执行一次
ReplicaManager#maybeShrinkIsr
// 尝试收缩ISR, 遍历所有在线状态的分区,检查是否需要收缩private def maybeShrinkIsr(): Unit = {allPartitions.keys.foreach { topicPartition =>nonOfflinePartition(topicPartition).foreach(_.maybeShrinkIsr())}}
如上所示,先遍历所有的分区,找出本台Broker上所有在线的分区 进行遍历,去尝试收缩ISR。
ReplicaManager#maybeShrinkIsr
/*** 尝试传播ISR变更**/def maybeShrinkIsr(): Unit = {val needsIsrUpdate = inReadLock(leaderIsrUpdateLock) {// 判断是否需要伸缩:当前分区是Leader&&(follower副本LEO!=Leader副本LEO && ( (currentTimeMs - followerReplica.lastCaughtUpTimeMs) > replica.lag.time.max.ms))needsShrinkIsr()}val leaderHWIncremented = needsIsrUpdate && inWriteLock(leaderIsrUpdateLock) {leaderLogIfLocal match {case Some(leaderLog) =>// 再获取一次 OSR, 有点双重检查锁的意思。val outOfSyncReplicaIds = getOutOfSyncReplicas(replicaLagTimeMaxMs)if (outOfSyncReplicaIds.nonEmpty) {val newInSyncReplicaIds = inSyncReplicaIds -- outOfSyncReplicaIds// 更新zk中的isr信息和cache中的isr信息shrinkIsr(newInSyncReplicaIds)// we may need to increment high watermark since ISR could be down to 1maybeIncrementLeaderHW(leaderLog)} else {false}case None => false // do nothing if no longer leader}}// some delayed operations may be unblocked after HW changedif (leaderHWIncremented)tryCompleteDelayedRequests()}
找到所有需要收缩的副本OSR,判断条件:
①.当前分区必须是Leader
②.follower副本LEO!=Leader副本LEO(如果相等的话,那表示跟Leader保持最高同步了,也就没必要收缩)
③.follower副本中,当前时间 - 上一次去leader获取数据的时间戳 > replica.lag.time.max.ms(2.5版本开始默认30000ms)
计算新的 newISR = 当前ISR - 1中获取到的OSR .
①. 将newISR组装一下成newLeaderData对象(还包含leader和epoche等信息),然后将信息写入到zk持久节点/brokers/topics/{Topic名称}/partitions/{分区号}/state中.
②.如果写入成功,则更新一下2个对象内存, isrChangeSet对象保存着ISR变更记录,lastIsrChangeMs记录这最新一次ISR变更的时间戳。一会这两个两个对象,在ISR传播的时候需要用到。
③.如果写入成功,则更新一下2个对象内存,inSyncReplicaIds=newISR, zkVersion = newVersion。
尝试增加HW(高水位), maybeIncrementLeaderHW 这个方法可能会在 ①.ISR变更 ②.任何副本的LEO更改 这两种情况下触发调用。当然我们这种场景触发是因为ISR变更了。如果HW有更新,则返回true,否则返回false,具体逻辑,请看下面。
如果3中更新成功,则触发一下待处理的延迟操作。这里包含一些fetch、produce、deleteRecords等延迟请求。
增加HW(高水位)的逻辑
Partition#maybeIncrementLeaderHW
/*** 尝试传播ISR变更**/private def maybeIncrementLeaderHW(leaderLog: Log, curTime: Long = time.milliseconds): Boolean = {inReadLock(leaderIsrUpdateLock) {// 先将leader的LEO 设置为 newHWvar newHighWatermark = leaderLog.logEndOffsetMetadata//遍历所有副本,找到最新的HW, 计算逻辑就是,在同步副本内的 最小LEO.remoteReplicasMap.values.foreach { replica =>if (replica.logEndOffsetMetadata.messageOffset < newHighWatermark.messageOffset &&// 要么在ISR里面,要么上一次Fetche数据距离现在<= replica.lag.time.max.ms(curTime - replica.lastCaughtUpTimeMs <= replicaLagTimeMaxMs || inSyncReplicaIds.contains(replica.brokerId))) {newHighWatermark = replica.logEndOffsetMetadata}}leaderLog.maybeIncrementHighWatermark(newHighWatermark) match {//打印一些日志,并返回是否更新成功。}}}
遍历所有的副本,找到 所有在ISR中的副本和 上一次Fetche数据距离现在<=replica.lag.time.max.ms时间但是还没有来得及进入ISR列表的副本, 然后从这些副本中找到最小的LEO newHW.
如果newHW > 当前Leader的LEO,抛异常,这种情况有问题。
将newHW 和 oldHW做个对比,如果满足下面任意一个条件,则更新 HW的值,否则不更新。
①.oldHW.messageOffset < newHW.messageOffset(新的HW>旧的HW)
②.oldHW.messageOffset==newHW.messageOffset&&oldHW.onOlderSegment(newHW)。 这里解释一下,当LogSegment滚动到新的Segment的时候,就会出现这种情况,更新一下HW(因为日志段变成新的了)
ISR 扩展
ISR的缩小,是有一个定时任务定时检查,而ISR扩展可不一样,它是在Follower副本向Leader副本发起 Fetch请求请求的时候会尝试检查是否需要重新加入到ISR中。
当发现Follower副本不在ISR列表的时候,就会执行下面的方法。
Partition#maybeExpandIsr
/*** 尝试传播ISR变更**/private def maybeExpandIsr(followerReplica: Replica, followerFetchTimeMs: Long): Unit = {//检查一下是否满足 扩展的条件val needsIsrUpdate = inReadLock(leaderIsrUpdateLock) {needsExpandIsr(followerReplica)}if (needsIsrUpdate) {inWriteLock(leaderIsrUpdateLock) {// 再坚持一遍是否需要伸展,双重检查。if (needsExpandIsr(followerReplica)) {val newInSyncReplicaIds = inSyncReplicaIds + followerReplica.brokerIdinfo(s"Expanding ISR from ${inSyncReplicaIds.mkString(",")} to ${newInSyncReplicaIds.mkString(",")}")// update ISR in ZK and cacheexpandIsr(newInSyncReplicaIds)}}}}//判断Follower副本是否有资格进入isr列表 followLEO>=HWprivate def isFollowerInSync(followerReplica: Replica, highWatermark: Long): Boolean = {val followerEndOffset = followerReplica.logEndOffsetfollowerEndOffset >= highWatermark && leaderEpochStartOffsetOpt.exists(followerEndOffset >= _)}
检查当前发起 Fetch请求 请求的Follower副本是否满足加入ISR的条件, 条件如下(与运算):
①. 当前副本不在ISR列表中
②. Follower的LEO>=HW(高水位) && Follower的LEO>= 当前Leader的LogStartOffset
如果满足条件,则开始执行 ISR扩展的流程,这里的流程跟上面 ISR缩小 的时候差不多。
①. 将newISR组装一下成newLeaderData对象(还包含leader和epoche等信息),然后将信息写入到zk持久节点/brokers/topics/{Topic名称}/partitions/{分区号}/state中.
②.如果写入成功,则更新一下2个对象内存, isrChangeSet对象保存着ISR变更记录,lastIsrChangeMs记录这最新一次ISR变更的时间戳。一会这两个两个对象,在ISR传播的时候需要用到。
③.如果写入成功,则更新一下2个对象内存,inSyncReplicaIds=newISR, zkVersion = newVersion。
❝ 那么, 上面的ISR伸缩,只是去zk上修改了ISR的数据和Controller里面的内存数据。 啥时候通知对应的Broker ISR已经变更了呢?
接下来我们来看看 ISR的广播
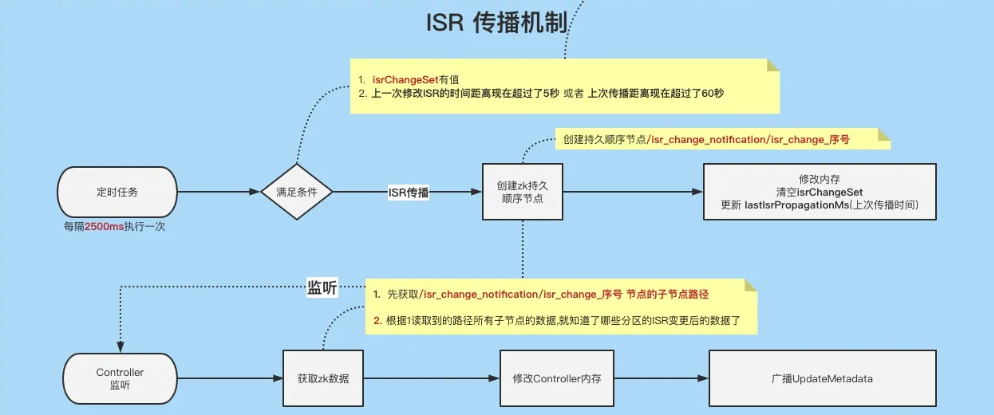
传播ISR maybePropagateIsrChanges
每隔2500毫秒就执行一次。
上面的ISR的收缩和扩展,最终呈现的结果是 修改ISR和内存,但是并没有通知到每个Broker。
只修改zk中的/brokers/topics/{Topic名称}/partitions/{分区号}/state节点,并不会通知集群,ISR已经变更了,因为正常情况下,Broker是没有去监听每一个state节点的。
因为在整个集群中,state节点太多了,一个分区一个,每个节点都去监听的话成本有点高
除了在分区副本重分配的时候,会去监听迁移的state节点,其他情况都没有监听。
❝ 那么,我们如何通知其他Broker ISR 变更了呢?
答案是:定时任务定时去传播ISR的变更。
ReplicaManager#maybePropagateIsrChanges
/*** 尝试传播ISR变更**/def maybePropagateIsrChanges(): Unit = {val now = System.currentTimeMillis()isrChangeSet synchronized {if (isrChangeSet.nonEmpty &&(lastIsrChangeMs.get() + ReplicaManager.IsrChangePropagationBlackOut < now ||lastIsrPropagationMs.get() + ReplicaManager.IsrChangePropagationInterval < now)) {zkClient.propagateIsrChanges(isrChangeSet)isrChangeSet.clear()lastIsrPropagationMs.set(now)}}}
判断是否满足传播条件,条件为下(同时满足)
①. 判断isrChangeSet不为空值,这里的isrChangeSet就是我们上面ISR收缩成功之后装填的值。
②. (lastIsrChangeMs(上次ISR变更时间) + 5000 < 当前时间)或者
(lastIsrPropagationMs(上次传播时间) + 60000< 当前时间)
总结: 有ISR变更过了&&(上一次ISR变更时间距离现在超过了5秒 || 上次传播时间距离现在超过了60秒)。
这避免了短时间内多次ISR变更发起多次传播。 当超过60秒都没有发起过传播,则立马发起传播。
开始传播!
传播的方式就是,创建一个顺序的持久节点/isrchange_notification/isr_change序号,节点内容就是 isrChangeSet。
清空isrChangeSet,更新 lastIsrPropagationMs(上次传播时间)
Controller监听/isrchange_notification/子节点
上面我们说因为正常情况下,Broker是没有去监听每一个state节点的(除了分区副本重分配),那么为了避免监听多个节点,只要有ISR变更就创建了/isr_change_notification/isr_change序号节点,Controller只需要监听这个节点就可以指定哪个ISR变更了。
这个跟动态配置那一块的处理逻辑是一样的。
KafkaController#processIsrChangeNotificationprivate def processIsrChangeNotification(): Unit = {def processUpdateNotifications(partitions: Seq[TopicPartition]): Unit = {val liveBrokers: Seq[Int] = controllerContext.liveOrShuttingDownBrokerIds.toSeqdebug(s"Sending MetadataRequest to Brokers: $liveBrokers for TopicPartitions: $partitions")sendUpdateMetadataRequest(liveBrokers, partitions.toSet)}if (!isActive) return// 去zk顺序节点/isr_change_notification 获取所有子节点的序号val sequenceNumbers = zkClient.getAllIsrChangeNotificationstry {// 拿到了子节点路径之后,就去zk查询所有子节点的数据。val partitions = zkClient.getPartitionsFromIsrChangeNotifications(sequenceNumbers)// 如果有的话,则做一些更新if (partitions.nonEmpty) {// 这里是去zk把变更过的Partitions 读取state节点的数据,然后重新加载到内存中updateLeaderAndIsrCache(partitions)//向所有Broker发送更新元数据的请求processUpdateNotifications(partitions)}} finally {// 处理完之后 把刚刚获取到的/isr_change_notification 子节点删除掉。zkClient.deleteIsrChangeNotifications(sequenceNumbers, controllerContext.epochZkVersion)}}
去zk获取/isr_change_notification节点的所有zk节点
根据获取到的子节点路径,然后再去zk读取这些子节点的数据
第2步骤拿到的是分区号,这时候根据分区号去对应的/brokers/topics/{Topic名称}/partitions/{分区号}/state节点读取新的数据, 然后将新的数据重载到当前Controller的内存中。
向所有Broker发 UpdateMetadata 请求
删除/isr_change_notification节点下面的数据。
节点数据结构 /isr_change_notification/isr_change_0000000001
{"version":1,"partitions":[{"topic":"Topic2","partition":0}]}