由于⽣产者⽣产的消息会不断追加到 log ⽂件末尾,为防⽌ log ⽂件过⼤导致数据定位效率低下,Kafka 采取了分⽚和索引机制。它将每个 Partition 分为多个 Segment,每个 Segment 对应两个⽂件:“.index” 索引⽂件和“.log” 数据⽂件。这种索引思想值得我们学习应用到平时的开发中。
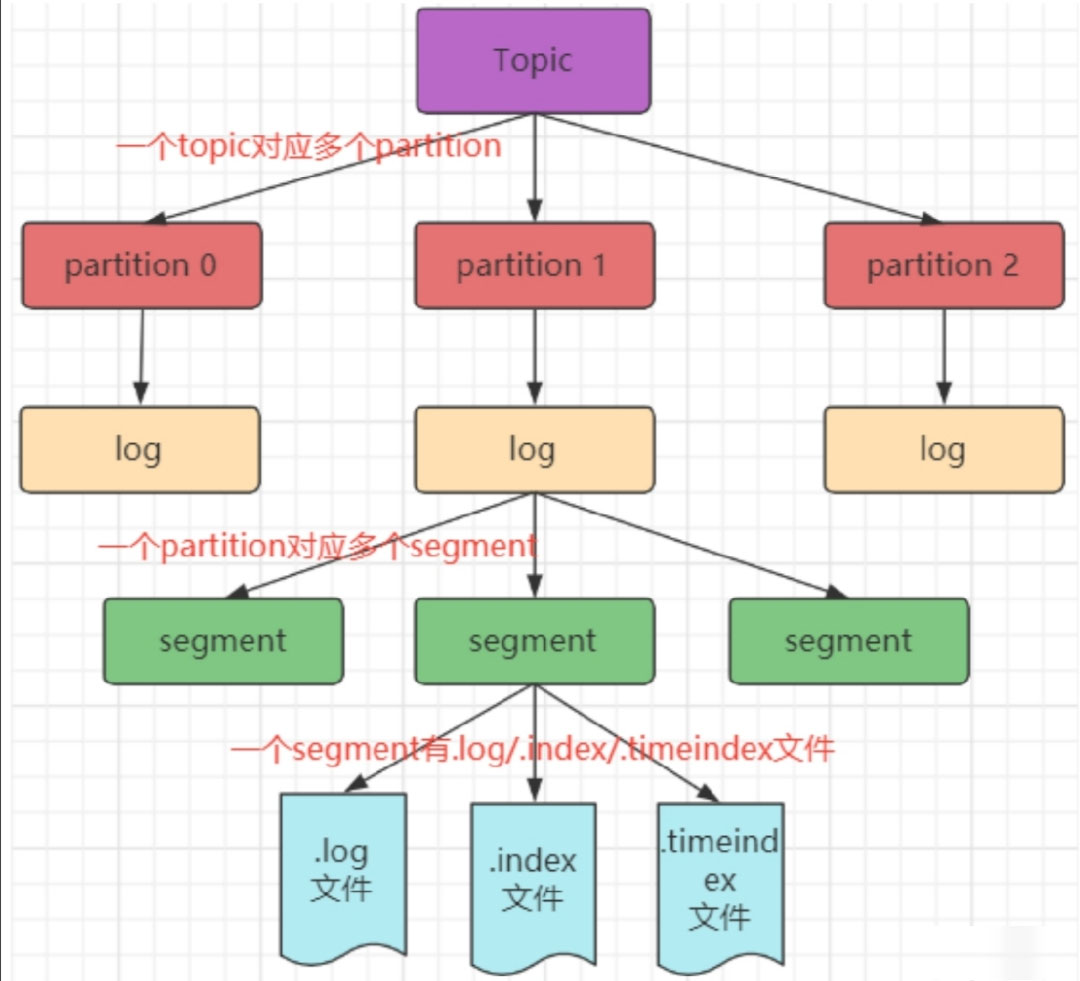
这些⽂件位于同⼀⽂件下,该⽂件夹的命名规则为:topic 名-分区号。例如,test这个 topic 有三个分区,则其对应的⽂件夹为 test-0,test-1,test-2。
$ ls /tmp/kafka-logs/test-100000000000000009014.index00000000000000009014.log00000000000000009014.timeindexleader-epoch-checkpoint
index 和 log ⽂件以当前 Segment 的第⼀条消息的 Offset 命名。下图为 index ⽂件和 log ⽂件的结构示意图
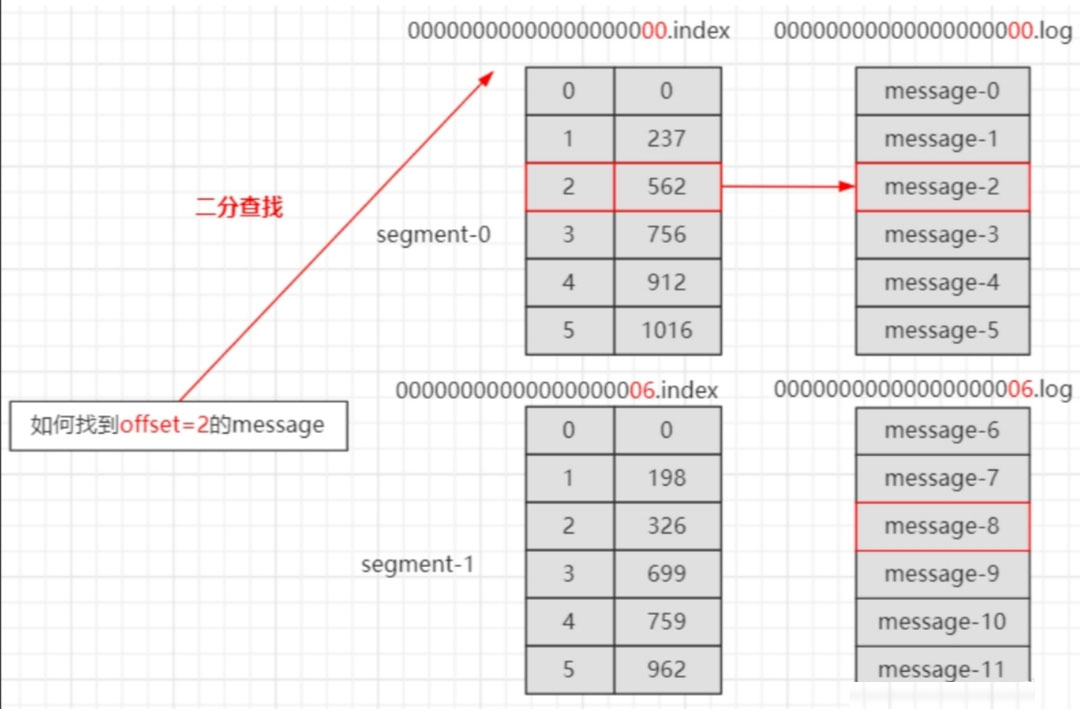
“.index” ⽂件存储⼤量的索引信息,“.log” ⽂件存储⼤量的数据,索引⽂件中的元数据指向对应数据⽂件中 Message 的物理偏移量。
使用shell命令查看索引
./kafka-dump-log.sh --files /tmp/kafka-logs/test-1/00000000000000000000.index




