虽然通过使用不同的字符集,我们可以在一台机器上查阅不同语言的文档,但是我们依然无法解决一个问题:如果一份文档中含有不同国家的不同语言的字符,那么就无法在一份文档中显示所有字符。为了解决这个问题,我们需要一个全人类达成共识的巨大的字符集,这就是 Unicode 字符集。
Unicode 字符集涵盖了目前人类使用的所有字符,并为每个字符进行了统一的编号,分配唯一的字符码(Code Point)。Unicode 字符集将所有字符按照使用上的频繁度划分为 17 个层面(Plane),每个层面上有 216=65536 个字符码空间。其中第 0 层面 BMP,基本涵盖了当今世界用到的所有字符。其他的层面要么是用来表示一些远古时期的文字,要么是留作扩展。我们平常用到的 Unicode 字符,一般都是位于 BMP 层面上的。目前 Unicode 字符集中尚有大量字符空间未使用。
在内存中每一个字符使用它在 Unicode 字符集中的唯一编码值表示,这是没有问题的。因为 Unicode 字符集中字符编码值的范围是 [0, 65535],在 Java 的 JVM 内存中无论这个字符的编码值是多少,都分配 2 个字节。
但是在其他环境中,如:文件、IO 流中,Unicode 就不完美了,主要有三个问题:
- ① 在文件或 IO 流中英文字母等 ASCII 码表中的字符只用一个字节表示,
- ② 如何才能区别这是 Unicode 和 ASCII,即计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢?
- ③ 如何和 GBK 等双字节编码方式一样,用最高位是 1 或 0 表示两个字节或一个字节,就少了很多值无法用于表示字符,不够表示所有字符。
Unicode 在很长一段时间内无法推广,直到互联网的出现,为解决 Unicode 如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8 就是每次 8 个位传输数据,而 UTF-16 就是每次 16 个位。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用 1~4 个字节表示一个符号。从 Unicode 到 UTF-8 并不是直接的对应,而是要过一些算法和规则来转换(即Uncidoe字符集≠UTF-8编码方式)。
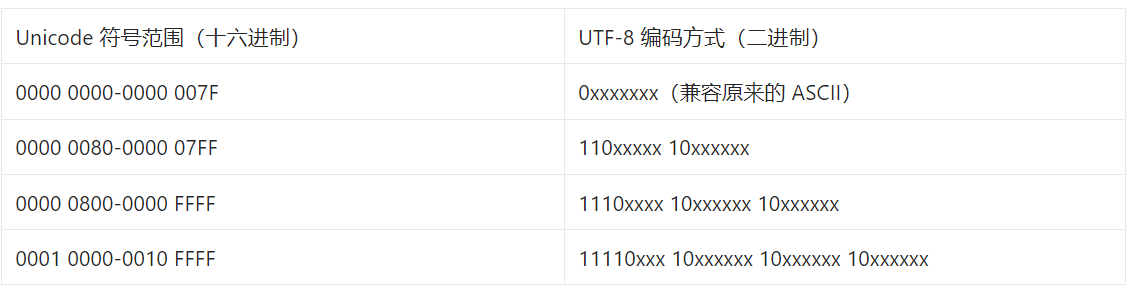
因此,Unicode 只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的编号,具体存储成什么样的字节流,取决于字符编码方案。推荐的 Unicode 编码是 UTF-16 和 UTF-8。
早期字符编码、字符集和代码页等概念都是表达同一个意思。例如:GB2312 字符集、GB2312 编码,936 代码页,实际上说的是同个东西。
但是对于 Unicode 则不同,Unicode 字符集只是定义了字符的集合和唯一编号,Unicode 编码,则是对 UTF-8、UCS-2/UTF-16 等具体编码方案的统称而已,并不是具体的编码方案。所以当需要用到字符编码的时候,你可以写gb2312,codepage936,utf-8,utf-16,但请不要写 Unicode。








