首页
技术小册
AIGC
面试刷题
技术文章
MAGENTO
云计算
视频课程
源码下载
PDF书籍
「涨薪秘籍」
登录
注册
认识ChatGPT
ChatGPT有多大的能力
认识ChatGPT的局限性
术语:提示与提示工程
如何挖掘提示工程的巨大威力
与ChatGPT的沟通模型
人工智能角度看提示工程
如何用AI改造工作
提示:分割指令和上下文
使用标记语言标记输入格式
利用有序列表与无序列表
将我们的需求量化
提示:要做什么和不要做什么
巧妙利用ChatGPT的接龙特性
与ChatGPT产生多轮对话
使用ChatGPT插件
什么是自然语言处理任务
文本摘要:提炼文本精华
文本纠错:检测和修正文本错误
情感分析:挖掘文本中的情感倾向
机器翻译:跨语言的文本转换
关键词抽取:从文本中识别主题
问题回答:用ChatGPT学知识
生成式任务:用ChatGPT做内容创作
BROKE框架介绍
背景:信息传达与角色设计
角色(Role):AI助手的角色扮演游戏
当前位置:
首页>>
技术小册>>
ChatGPT与提示工程(上)
小册名称:ChatGPT与提示工程(上)
2022年11月,OpenAI推出了人工智能聊天机器人ChatGPT。该产品发布后,立刻引起了学术界和工业界的广泛关注,并逐渐成为全世界的焦点。 ChatGPT是一个强大的聊天机器人,一种人工智能模型,也是一种自然语言处理工具,全称为“Chat Generative Pre-trained Transformer”。 通过大量文本数据训练,ChatGPT学会了理解和生成人类语言。你可以和它交流各种话题,如电影、音乐、体育、科学、艺术相关的内容等;你也可以向它提出各种请求,如让它写一首诗、编一个故事、画一幅画等。ChatGPT会尽力满足你的需求,并且保持友好、有趣、有礼貌的态度。 需要注意的是,通常我们在谈到ChatGPT时,可能指的是2022年11月发布的最初引起轰动的GPT-3.5版本。由于OpenAI公司已经在2023年3月发布了更聪明、更强大的GPT-4,本书中的案例讲解均使用GPT-4模型,在提示工程部分的章节中,我们提到的ChatGPT也是指GPT-4。 不过,本书中介绍的提示工程方法对这两者,以及类似的其他大语言模型同样适用。 1.1.1 什么是语言模型 我们每天都在使用语言——无论是聊天、阅读、写作,还是思考。语言是人类最重要的沟通工具。我们可以借助所谓的“语言模型”(Language Model)来让计算机学习、理解和使用语言,而ChatGPT就是这样一种语言模型。 那么,语言模型是什么呢?语言模型可以理解为一种预测下一个token(自然语言处理的单位,可以简单理解为词)的统计模型。举例来说,如果我们输入“想吃”,语言模型会预测“饭”是接下来很有可能出现的词。因为根据它训练过的大量数据资料显示,“想吃饭”是一个很常见的短语,在数据资料中出现“想吃饭”短语的频率要高于“想吃鼠标”等短语。 再如,如果我们输入“今天天气很”,语言模型可能会预测“好”“差”等形容词,因为语言模型在训练过程中前面短语出现的情况下,后面这些词的出现频率很高。 简而言之,语言模型会根据我们输入的词序列,结合它见过的所有词序列组合,再根据词序列组合出现的频率,来预测下一个最有可能出现的词是什么。根据语言样本进行概率分布估计,就是语言模型。 那么,语言模型究竟长什么样子呢?为了帮助理解,简单打一个比方:你可以想象有一张巨大的表格,这张表格列出了所有词序列的组合,以及词序列对应组合出现的频率。当我们输入某个词序列时,语言模型会在这张表格里找出与之最匹配的词序列,并预测出其后面最常见的一个词。 当然,真实的语言模型远比表格复杂。它使用神经网络和深度学习算法来构建自己的“表格”,涉及上百万个词和词序列,还考虑了上下文语义等因素。但理论上,它所做的事情仍然是预测下一个最有可能出现的词。 虽然用机器“预测下一个词”的工作听起来简单得不可思议,但是结果却是产生了ChatGPT这样的划时代人工智能产品。 严格来说,ChatGPT属于语言模型中的大语言模型(Large Language Model,LLM)。语言模型的类型和对应的简单说明如表1.1所示。 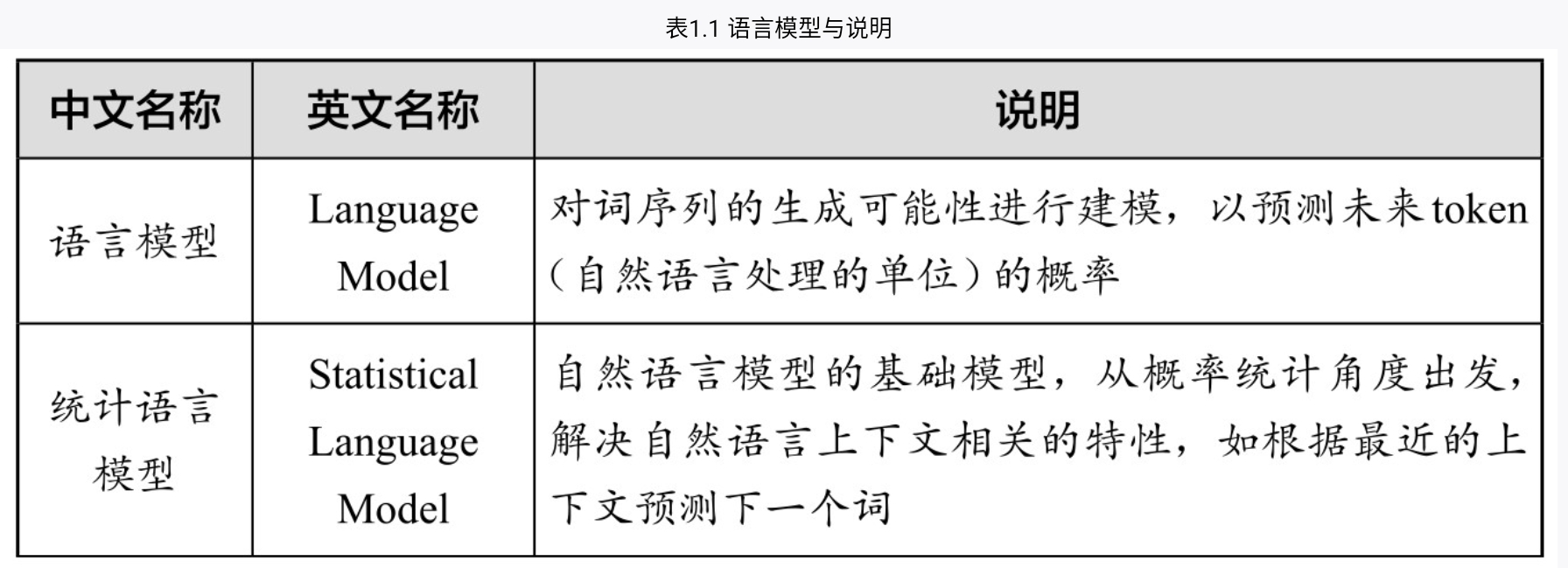 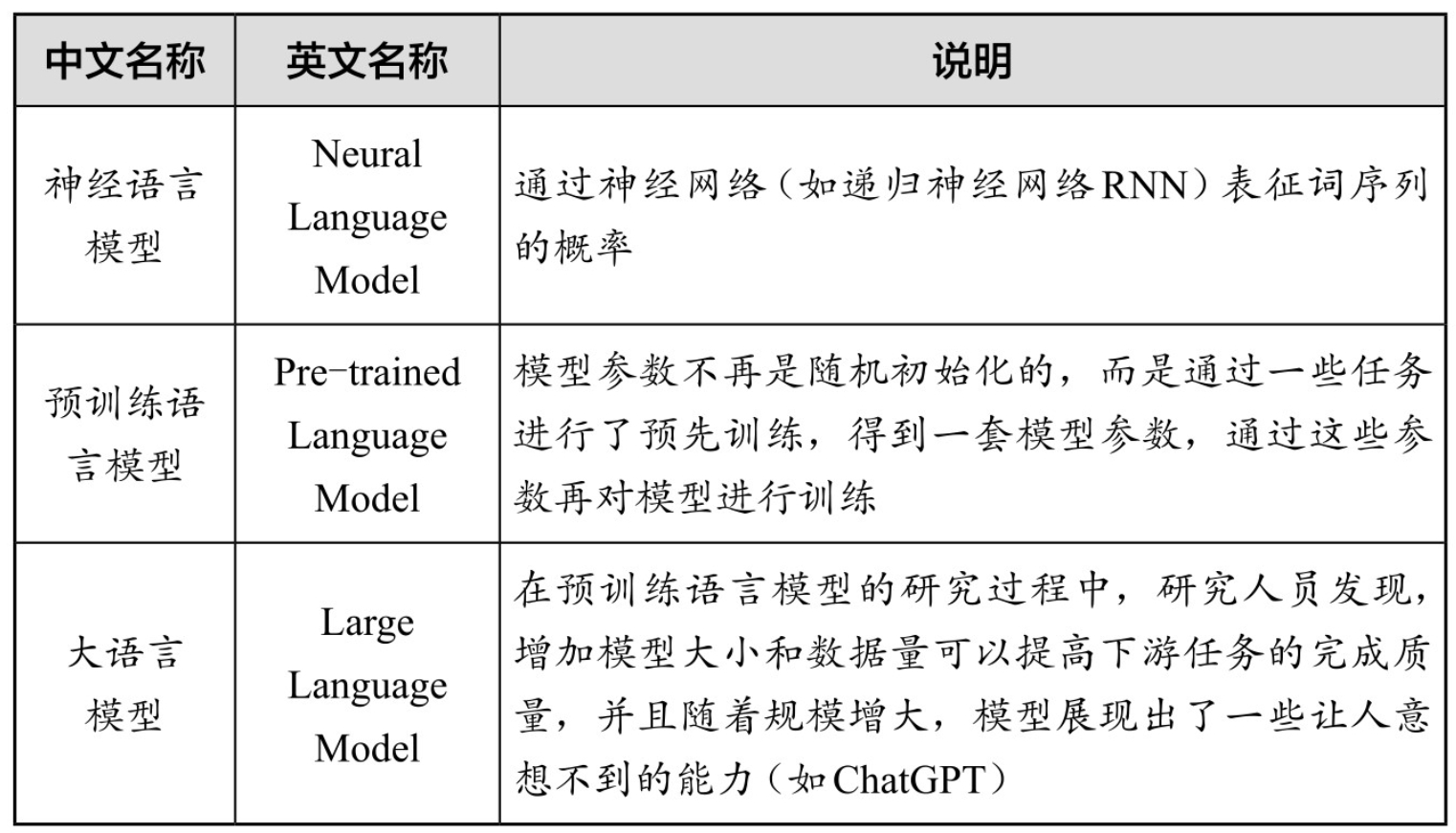 1.1.2 什么是GPT 要进一步了解ChatGPT,我们需要先将视线放在这个词的后半部分,也就是“GPT”三个字母上。 GPT是Generative Pre-trained Transformer的缩写,中文释译为“生成式预训练变换模型”。 1.Generative(生成式) GPT是一种生成式人工智能。它通过计算大量数据中的概率分布,最终可以从分布中生成新的数据。所以,GPT可以用于各种任务,如写作、翻译、回答问题等。 2.Pre-trained(预训练) Pre-trained即预训练,指的是GPT模型的一种训练方式。预训练是指在训练特定任务的模型之前,先在大量的数据上进行训练,以学习一些基础的、通用的特征或模式。用于预训练的数据通常是未标注过的,这意味着模型需要自我发现数据中的规律和结构,而不是依赖已标注的信息进行学习。使用无标注数据的训练方式通常被称为“无监督学习”。 这个预训练过程使得GPT能够学习到语言的一般模式和结构。然后, GPT可以通过在有标签的数据上进行微调,来适应各种不同的任务。  3.Transformer Transformer直译成中文可以是“改变者”“变换器”,甚至是“变形金刚”,这是GPT的基础架构。Transformer是一种深度学习模型,它使用自注意力机制来处理序列数据。这使得GPT能够有效地处理长文本,并捕捉到文本中的复杂模式。 那什么是自注意力机制呢?自注意力机制(Self-Attention)是Transformer的核心组成部分。这种机制的主要思想是在处理序列的每个元素时,不仅考虑该元素本身,还考虑与其相关的其他元素。 Transformer可以为语言模型提供一种“有的放矢”的能力,它可以对输入的文本中的每个词分配不同的重要性权重,然后进行权重比较,从而帮助模型理解文本中各词之间的依赖和关联关系,使其不再机械地对待每一个词,而是可以像人类一样有选择性地关注与理解信息。[1] 所以,当我们说“GPT”时,其实指的是一种能够生成新的连贯文本(可以回答问题、写作、进行聊天),在大量数据上进行预训练(知识丰富、学富五车、什么都知道),并使用Transformer架构(能够捕捉文本中各词之间的依赖和关联关系)的深度学习模型。 2017年,谷歌发布了关于Transformer的论文;2018年,OpenAI发布了GPT-1;2020年,OpenAI发布了GPT-3。此后,OpenAI在GPT-3的基础上又进行了人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)和监督精调(Supervised Fine-tuning)。数次迭代后, ChatGPT(GPT-3.5)就这样训练成了,并在2022年11月发布,引起了全世界的轰动。
下一篇:
ChatGPT有多大的能力
该分类下的相关小册推荐:
人工智能超入门丛书--知识工程
企业AI之旅:深度解析AI如何赋能万千行业
人工智能原理、技术及应用(下)
巧用ChatGPT快速搞定数据分析
ChatGPT商业变现
人工智能原理、技术及应用(上)
可解释AI实战PyTorch版(上)
ChatGPT大模型:技术场景与商业应用(下)
Midjourney新手攻略
ChatGPT大模型:技术场景与商业应用(中)
深度学习与大模型基础(上)
ChatGLM3大模型本地化部署、应用开发与微调(中)









