很多时候,我们拿到手的数据都包含大量的数值型变量,在对数值型变量进行探索和分析时,一般都会应用到可视化方法。而本节的重点就是介绍如何使用Python实现数值型变量的可视化,通过本节内容的学习,读者将会掌握如何使用matplotlib模块、pandas模块和seaborn模块绘制直方图、核密度图、箱线图、小提琴图、折线图以及面积图。
6.2.1 直方图与核密度曲线
直方图一般用来观察数据的分布形态,横坐标代表数值的均匀分段,纵坐标代表每个段内的观测数量(频数)。一般直方图都会与核密度图搭配使用,目的是更加清晰地掌握数据的分布特征,下面将详细介绍该类型图形的绘制。
1.matplotlib模块
plt.hist(x, bins=10, range=None, normed=False,weights=None, cumulative=False, bottom=None,histtype='bar', align='mid', orientation='vertical',rwidth=None, log=False, color=None,label=None, stacked=False)

这里不妨以Titanic数据集为例绘制乘客的年龄直方图,具体代码如下:

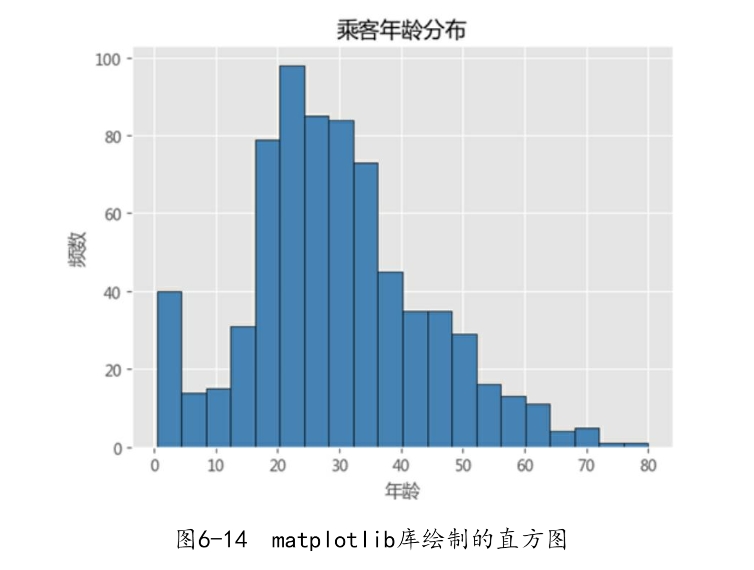
如图6-14所示,就是关于乘客年龄的直方图分布。需要注意的是,如果原始数据集中存在缺失值,一定要对缺失观测进行删除或替换,否则无法绘制成功。如果在直方图的基础上再添加核密度图,通过matplotlib模块就比较吃力了,因为首先得计算出每一个年龄对应的核密度值。为了简单起见,下面利用pandas模块中的plot方法将直方图和核密度图绘制到一起。
2.pandas模块

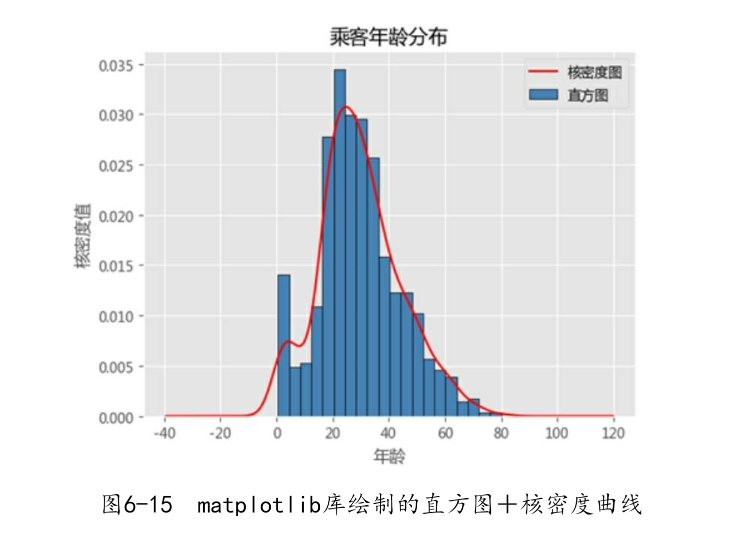
如图6-15所示,Python的核心代码就两行,分别是利用plot方法绘制直方图和核密度图。需要注意的是,在直方图的基础上添加核密度图,必须将直方图的频数更改为频率,即normed参数设置为True。
3.seaborn模块
尽管这幅图满足了两种图形的合成,但其表达的是所有乘客的年龄分布,如果按性别分组,研究不同性别下年龄分布的差异,该如何实现?针对这个问题,使用matplotlib模块或pandas模块都会稍微复杂一些,推荐使用seaborn模块中的distplot函数,因为该函数的代码简洁而易懂。关于该函数的语法和参数含义如下:
sns.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None,hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,color=None, vertical=False, norm_hist=False, axlabel=None,label=None, ax=None)

从函数的参数可知,通过该函数,可以实现三种图形的合成,分别是直方图(hist参数)、核密度曲线(kde参数)以及指定的理论分布密度曲线(fit参数)。接下来,针对如上介绍的distplot函数,绘制不同性别下乘客的年龄分布图,具体代码如下:

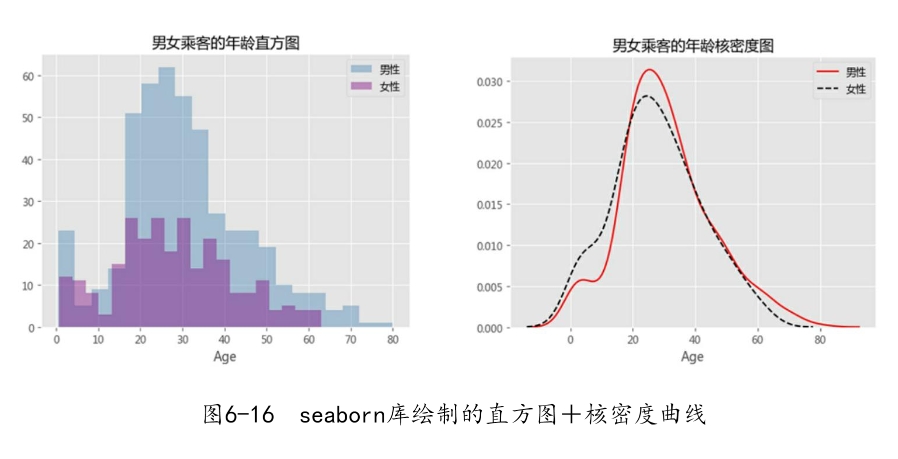
如图6-16所示,为了避免四个图形混在一起不易发现数据背后的特征,将直方图与核密度图分开绘制。从直方图来看,女性年龄的分布明显比男性矮,说明在各年龄段下,男性乘客要比女性乘客多;再看核密度图,男女性别的年龄分布趋势比较接近,说明各年龄段下的男女乘客人数同步增加或减少。
6.2.2 箱线图
箱线图是另一种体现数据分布的图形,通过该图可以得知数据的下须值(Q1-1.5IQR)、下四分位数(Q1)、中位数(Q2)、均值、上四分位(Q3)数和上须值(Q3+1.5IQR),更重要的是,箱线图还可以发现数据中的异常点。箱线图的绘制仍然可以通过matplotlib模块、pandas模块和seaborn模块完成,下面将一一介绍各模块绘制条形图的过程。
1.matplotlib模块
首先介绍一下matplotlib模块中绘制箱线图的boxplot函数,有关该函数的语法和参数含义如下:
plt.boxplot(x, notch=None, sym=None, vert=None,whis=None, positions=None, widths=None,patch_artist=None, meanline=None, showmeans=None,showcaps=None, showbox=None, showfliers=None,boxprops=None, labels=None, flierprops=None,medianprops=None, meanprops=None,capprops=None, whiskerprops=None)

为读者方便理解boxplot函数的用法,这里以某平台二手房数据为例,运用箱线图探究其二手房单价的分布情况,具体代码如下:

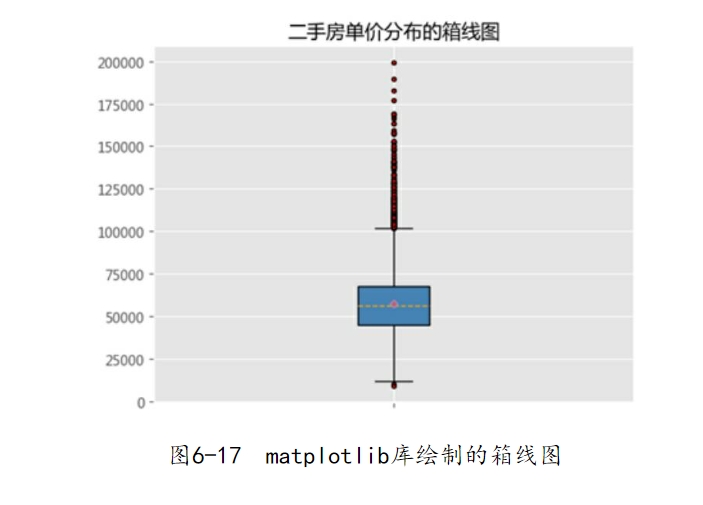
如图6-17所示,图中的上下两条横线代表上下须、箱体的上下两条横线代表上下四分位数、箱体中的虚线代表中位数、箱体中的点则为均值、上下须两端的点代表异常值。通过图中均值和中位数的对比就可以得知数据微微右偏(判断标准:如果数据近似正态分布,则众数=中位数=均值;如果数据右偏,则众数<中位数<均值;如果数值左偏,则众数>中位数>均值)。
如上绘制的是二手房整体单价的箱线图,这样的箱线图可能并不常见,更多的是分组箱线图,即二手房的单价按照其他分组变量(如行政区域、楼层、朝向等)进行对比分析。下面继续使用matplotlib模块对二手房的单价绘制分组箱线图,代码如下:

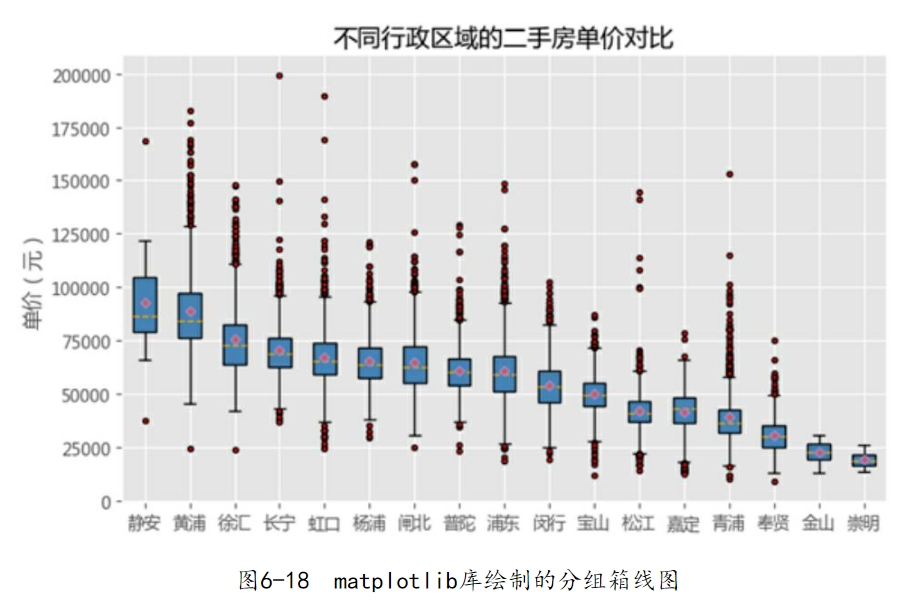
应用matplotlib模块绘制如上所示的分组箱线图会相对烦琐一些,由于boxplot函数每次只能绘制一个箱线图,为了能够实现多个箱线图的绘制,对数据稍微做了一些变动,即将每个行政区域下的二手房单价汇总到一个列表中,然后基于这个大列表应用boxplot函数。在绘图过程中,首先做了一个“手脚”,那就是统计各行政区域二手房的平均单价,并降序排序,这样做的目的就是让分组箱线图能够降序呈现。
虽然pandas模块中的plot方法可以绘制分组箱线图,但是该方法是基于数据框执行的,并且数据框的每一列对应一个箱线图。对于二手房数据集来说,应用plot方法绘制分组箱线图不太合适,因为每一个行政区的二手房数量不一致,将导致无法重构一个新的数据框用于绘图。
2.seaborn模块
如果读者觉得matplotlib模块绘制分组箱线图比较麻烦,可以使用seaborn模块中的boxplot函数。下面不妨先了解一下该函数的参数含义:
sns.boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,orient=None, color=None, palette=None, saturation=0.75, width=0.8,dodge=True, fliersize=5, linewidth=None, whis=1.5, notch=False, ax=None, **kwargs)

这里仍以上海二手房数据为例,应用seaborn模块中的boxplot函数绘制分组箱线图,详细代码如下:

通过如上代码,同样可以得到完全一致的分组箱线图。这里建议读者不要直接学习和使用pandas模块和seaborn模块绘制统计图形,而是先把matplotlib模块摸透,因为Python的核心绘图模块是matplotlib。
6.2.3 小提琴图
小提琴图是比较有意思的统计图形,它将数值型数据的核密度图与箱线图融合在一起,进而得到一个形似小提琴的图形。尽管matplotlib模块也提供了绘制小提琴图的函数violinplot,但是绘制出来的图形中并不包含一个完整的箱线图,所以本节将直接使用seaborn模块中的violinplot函数绘制小提琴图。首先,带领读者了解一下有关violinplot函数的语法和参数含义:
sns.violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,bw='scott', cut=2, scale='area', scale_hue=True, gridsize=100,width=0.8, inner='box', split=False, dodge=True, orient=None,linewidth=None, color=None, palette=None, saturation=0.75, ax=None)

接下来,以酒吧的消费数据为例(数据包含客户的消费金额、消费时间、打赏金额、客户性别、是否抽烟等字段),利用如上介绍的函数绘制分组小提琴图,以帮助读者进一步了解参数的含义,绘图代码如下:
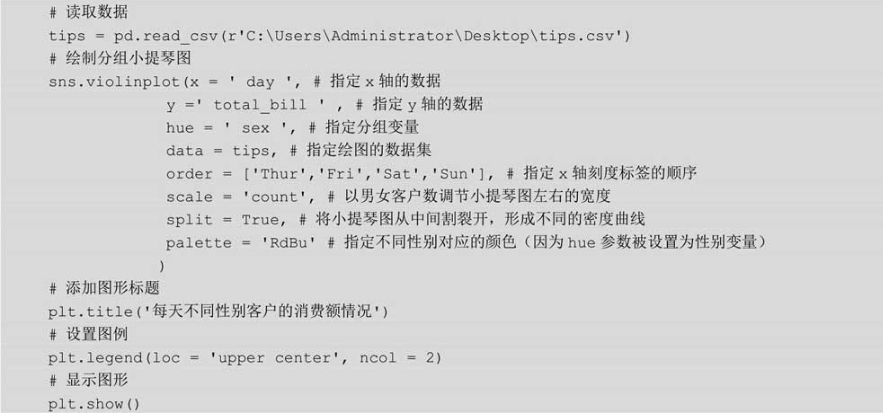
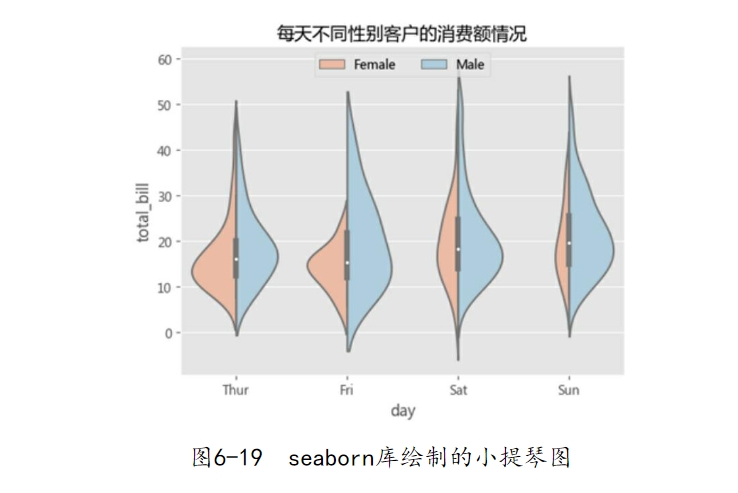
如图6-19所示,得到了分组的小提琴图,读者会发现,小提琴图的左右两边并不对称,是因为同时使用了hue参数和split参数,两边的核密度图代表了不同性别客户的消费额分布。从这张图中,一共可以反映四个维度的信息,y轴表示客户的消费额、x轴表示客户的消费时间、颜色图例表示客户的性别、左右核密度图的宽度代表了样本量。以周五和周六两天为例,周五的男女客户数量差异不大,而周六男性客户要比女性客户多得多,那是因为右半边的核密度图更宽一些。
6.2.4 折线图
对于时间序列数据而言,一般都会使用折线图反映数据背后的趋势。通常折线图的横坐标指代日期数据,纵坐标代表某个数值型变量,当然还可以使用第三个离散变量对折线图进行分组处理。接下来仅使用Python中的matplotlib模块和pandas模块实现折线图的绘制。尽管seaborn模块中的tsplot函数也可以绘制时间序列的折线图,但是该函数非常不合理,故不在本节中介绍。
1.matplotlib模块
折线图的绘制可以使用matplotlib模块中的plot函数实现。关于该函数的语法和参数含义如下:
plt.plot(x, y, linestyle, linewidth, color, marker,markersize, markeredgecolor, markerfactcolor,markeredgewidth, label, alpha)

为了进一步理解plot函数中的参数含义,这里以某微信公众号的阅读人数和阅读人次为例(数据包含日期、人数和人次三个字段),绘制2017年第四季度微信文章阅读人数的折线图,代码如下:

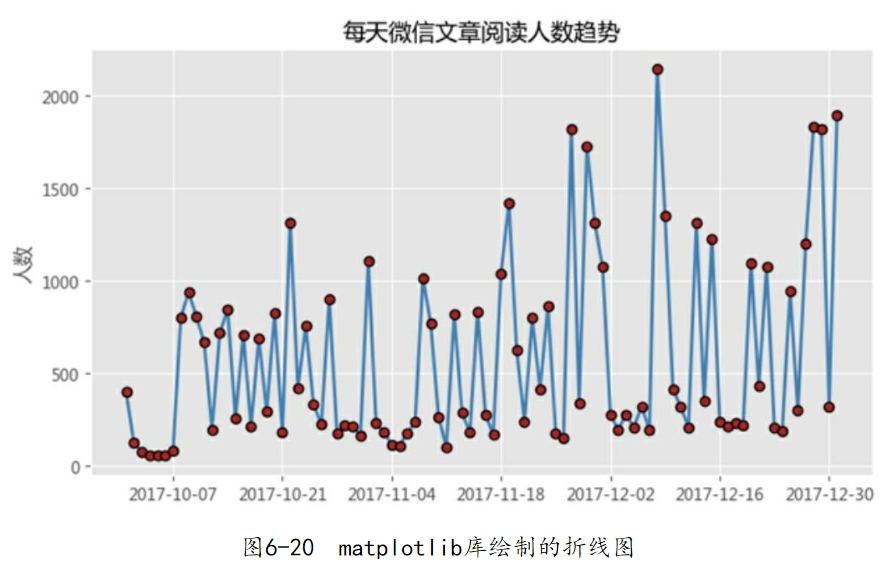
如图6-20所示,在绘制折线图的同时,也添加了每个数据对应的圆点。读者可能会注意到,代码中折线类型和点类型分别用一个减号-(代表实线)和字母o(代表空心圆点)表示。是否还有其他的表示方法?这里将常用的线型和点型汇总到表6-1和表6-2中。
虽然上面的图形可以反映有关微信文章阅读人数的波动趋势,但是为了进一步改进这个折线图,还需要解决两个问题:
如何将微信文章的阅读人数和阅读人次同时呈现在图中。
对于x轴的刻度标签,是否可以只保留月份和日期,并且以7天作为间隔。

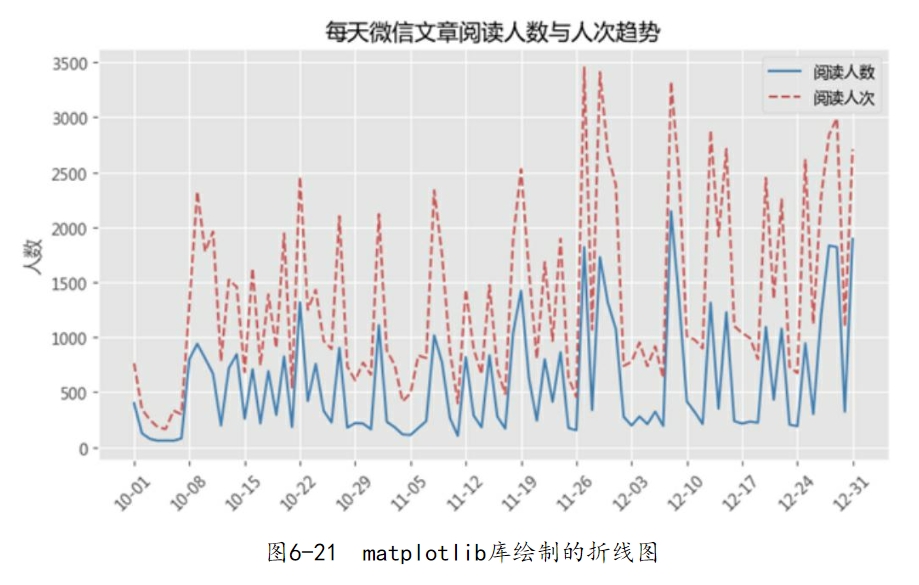
如图6-21所示,恰到好处地解决了之前提出的两个问题。上面的绘图代码可以分解为两个核心部分:
运用两次plot函数分别绘制阅读人数和阅读人次的折线图,最终通过plt.show()将两条折线呈现在一张图中。
日期型轴刻度的设置,ax变量用来获取原始状态的轴属性,然后基于ax对象修改刻度的显示方式,一个是仅包含月日的格式,另一个是每7天作为一个间隔。
2.pandas模块
如果使用pandas模块绘制折线图,调用的仍然是plot方法,接下来以2015—2017年上海每天的最高气温数据为例,绘制每月平均最高气温的三条折线图,具体代码如下:
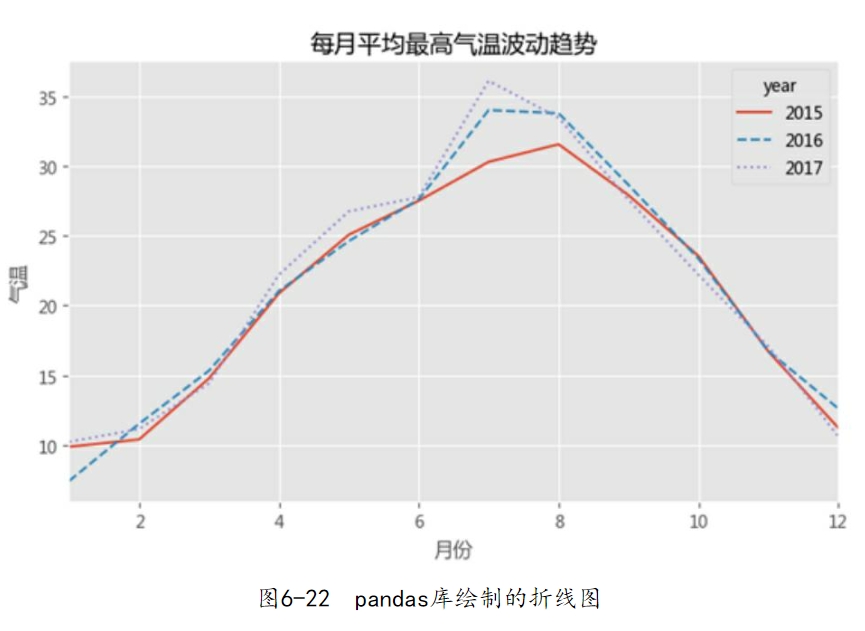
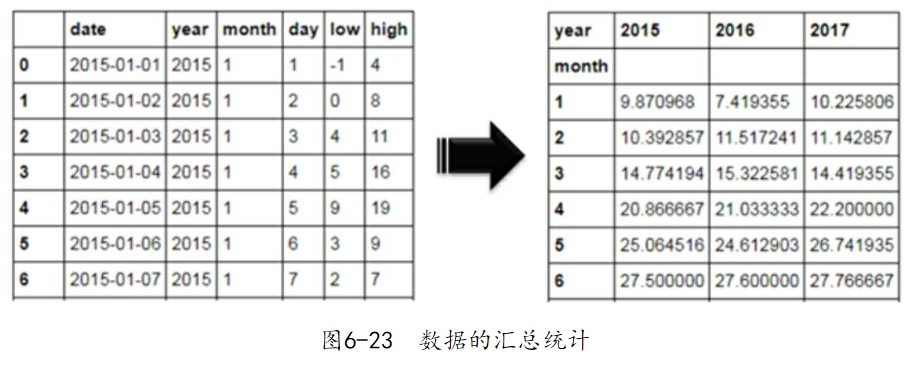
如图6-22所示,图中表示的是各年份中每月平均最高气温的走势,虽然绘图的核心部分(plot过程)很简单,但是前提需要将原始数据集转换成可以绘制多条折线图的格式,即构成三条折线图的数据分别为数据框的三个字段。为了构造特定需求的数据集,使用了数据框的pivot_table方法,形成一张满足条件的透视表。图6-23所示就是数据集转换的前后对比。