如果你需要使用数据可视化的方法来表达离散型变量的分布特征,例如统计某APP用户的性别比例、某产品在各区域的销售量分布、各年龄段内男女消费者的消费能力差异等。对于类似这些离散型变量的统计描述,可以使用饼图或者条形图对其进行展现。接下来,通过具体的案例来学习饼图和条形图的绘制,进而掌握Python的绘图技能。
6.1.1 饼图
饼图属于最传统的统计图形之一(1801年由William Playfair首次发布使用),它几乎随处可见,例如大型公司的屏幕墙、各种年度论坛的演示稿以及各大媒体发布的数据统计报告等。
首先,需要读者了解有关饼图的原理。饼图是将一个圆分割成不同大小的楔形,而圆中的每一个楔形代表了不同的类别值,通常会根据楔形的面积大小来判断类别值的差异。如图6-1所示,就是一个由不同大小的楔形组成的饼图。
对于这样的饼图,该如何通过Python完成图形的绘制呢?其实很简单,通过matplotlib模块和pandas模块都可以非常方便地得到一个漂亮的饼图。下面举例说明如何利用Python实现饼图的绘制。
1.matplotlib模块
如果你选择matplotlib模块绘制饼图的话,首先需要导入该模块的子模块pyplot,然后调用模块中的pie函数。关于该函数的语法和参数含义如下:
pie(x, explode=None, labels=None, colors=None,autopct=None, pctdistance=0.6, shadow=False,labeldistance=1.1, startangle=None,radius=None, counterclock=True, wedgeprops=None,textprops=None, center=(0, 0), frame=False)

该函数的参数虽然比较多,但是应用起来非常灵活,而且绘制的饼图也比较好看。下面以“芝麻信用”失信用户数据为例(数据来源于财新网),分析近300万失信人群的学历分布,pie函数绘制饼图的详细代码如下:
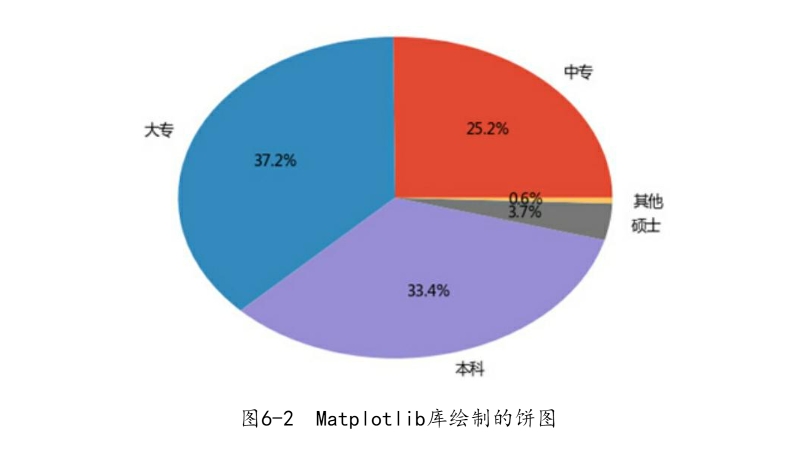
图6-2所示就是一个不加任何修饰的饼图。这里只给pie函数传递了三个核心参数,即绘图的数据、每个数据代表的含义(学历标签)以及给饼图添加数值标签。很显然,这样的饼图并不是很完美,例如饼图看上去并不成正圆、饼图没有对应的标题、没有突出显示饼图中的某个部分等。下面进一步对该饼图做一些修饰,尽可能让饼图看起来更加舒服,代码如下:

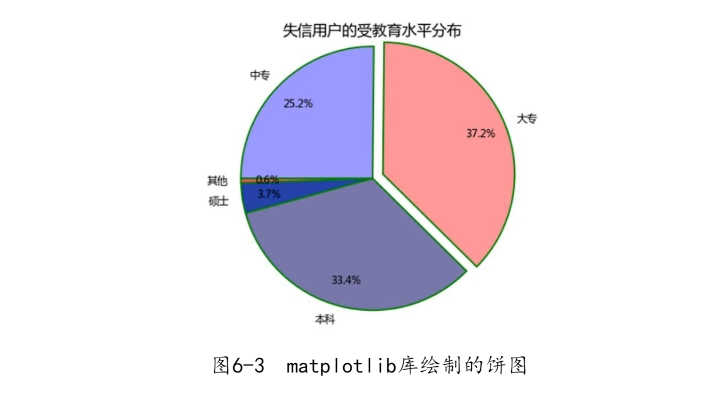
如上呈现的饼图,直观上要比之前的饼图好看很多,这些都是基于pie函数的灵活参数所实现的。饼图中突出显示大专学历的人群,是因为在这300万失信人群中,大专学历的人数比例最高,该功能就是通过explode参数完成的。另外,还需要对如上饼图的绘制说明几点:
如果绘制的图形中涉及中文及数字中的负号,都需要通过rcParams进行控制。由于不加修饰的饼图更像是一个椭圆,所以需要pyplot模块中的axes函数将椭圆强制为正圆。
自定义颜色的设置,既可以使用十六进制的颜色,也可以使用具体的颜色名称,如red、black等。
如果需要添加图形的标题,需要调用pyplot模块中的title函数。代码plt.show()用来呈现最终的图形,无论是使用Jupyter或Pycharm编辑器,都需要使用这行代码呈现图形。
2.pandas模块
细心的读者一定会发现,在前面的几个章节中或多或少地应用到pandas模块的绘图“方法”plot,该方法可以针对序列和数据框绘制常见的统计图形,例如折线图、条形图、直方图、箱线图、核密度图等。同样,plot也可以绘制饼图,接下来简单介绍一下该方法针对序列的应用和参数含义:
Series.plot(kind='line', ax=None, figsize=None, use_index=True, title=None,grid=None, legend=False, style=None, logx=False, logy=False,loglog=False, xticks=None, yticks=None, xlim=None, ylim=None,rot=None, fontsize=None, colormap=None, table=False, yerr=None,xerr=None, label=None, secondary_y=False, **kwds)

pandas模块中的plot“方法”可以根据kind参数绘制不同的统计图形,而且也包含了其他各种灵活的参数。除此,根据不同的kind参数值,可以调用更多对应的关键字参数**kwds,这些关键字参数都源于pyplot中的绘图函数。
为了帮助读者更好地理解plot方法绘制的统计图形,这里仍然以失信用户数据为例,绘制学历的分布饼图,详细代码如下:

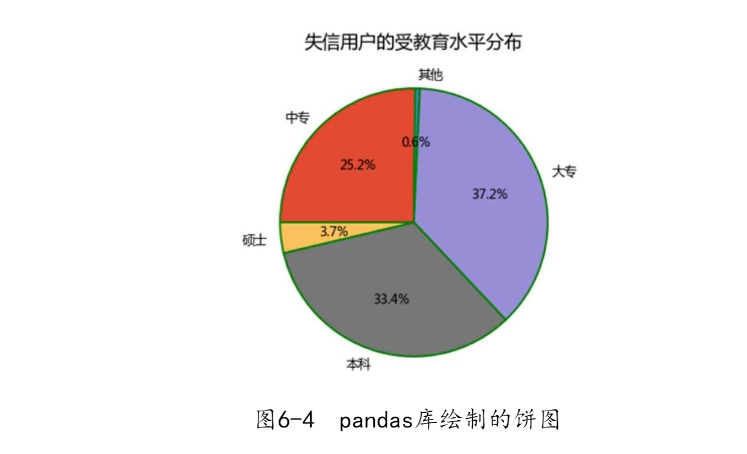
如图6-4所示,应用pandas模块中的plot方法,也可以得到一个比较好看的饼图。该方法中除了kind参数和title参数属于plot方法,其他参数都是pyplot模块中pie函数的参数,并且以关键字参数的形式调用。
6.1.2 条形图
虽然饼图可以很好地表达离散型变量在各水平上的差异(如会员的性别比例、学历差异、等级高低等),但是其不擅长对比差异不大或水平值过多的离散型变量,因为饼图是通过各楔形面积的大小来表示数值的高低,而人类对扇形面积的比较并不是特别敏感。如果读者手中的数据恰好不适合用饼图展现,可以选择另一种常用的可视化方法,即条形图。
以垂直条形图为例,离散型变量在各水平上的差异就是比较柱形的高低,柱体越高,代表的数值越大,反之亦然。在Python中,可以借助matplotlib、pandas和seaborn模块完成条形图的绘制。下面将采用这三个模块绘制条形图。
1.matplotlib模块
应用matplotlib模块绘制条形图,需要调用bar函数,关于该函数的语法和参数含义如下:
bar(left, height, width=0.8, bottom=None, color=None, edgecolor=None,linewidth=None, tick_label=None, xerr=None, yerr=None,label = None, ecolor=None, align, log=False, **kwargs)

bar函数的参数同样很多,希望读者能够认真地掌握每个参数的含义,以便使用时得心应手。下面将基于该函数绘制三类条形图,分别是单变量的垂直或水平条形图、堆叠条形图和水平交错条形图。
(1)垂直或水平条形图
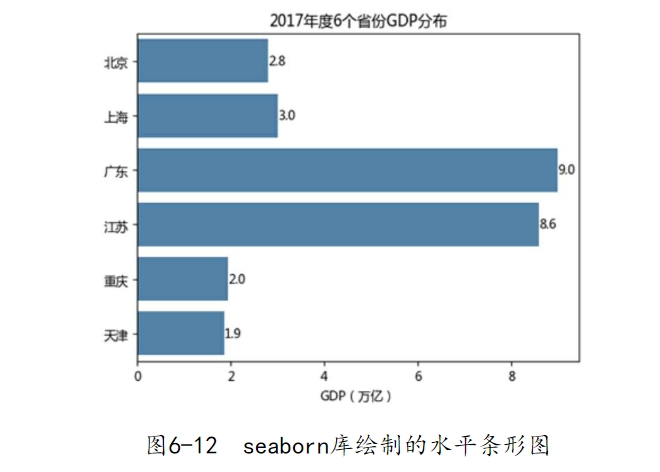
首先来绘制单个离散变量的垂直或水平条形图,数据来源于互联网,反映的是2017年中国六大省份的GDP,绘图代码如下:


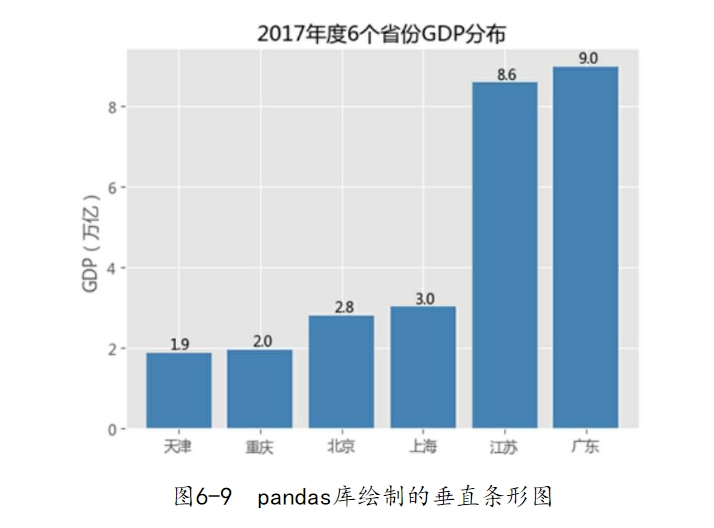
如图6-5所示,该条形图比较清晰地反映了6个省份GDP的差异。针对如上代码需要做几点解释:
条形图中灰色网格的背景是通过代码plt.style.use(‘ggplot’)实现的,如果不添加该行代码,则条形图为白底背景。
如果添加图形的x轴或y轴标签,需要调用pyplot子模块中的xlab和ylab函数。由于bar函数没有添加数值标签的参数,因此使用for循环对每一个柱体添加数值标签,使用的核心函数是pyplot子模块中的text。该函数的参数很简单,前两个参数用于定位字符在图形中的位置,第三个参数表示呈现的具体字符值,第四个参数为ha,表示字符的水平对齐方式为居中对齐。
站在阅读者的角度来看,该条形图可能并不是很理想,因为不能快速地发现哪个省份GDP最高或最低。如果将该条形图进行降序或升序处理,可能会更直观一些。这里就以水平条形图为例,代码如下:

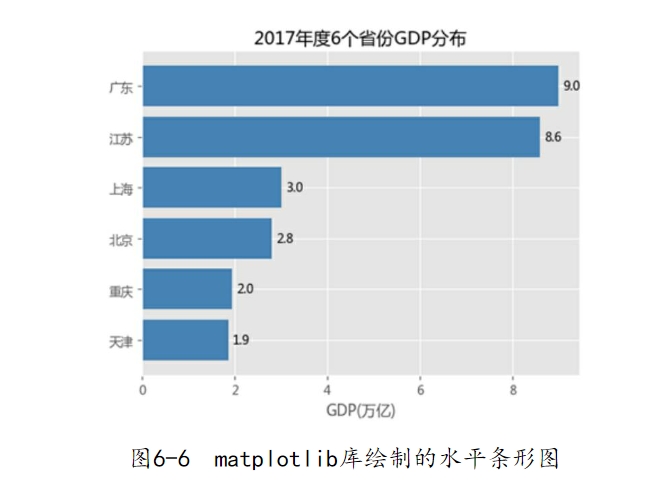
图6-6所示就是经过排序的水平条形图(实际上是垂直条形图的轴转置)。需要注意的是,水平条形图不再是bar函数,而是barh函数。读者可能疑惑,为什么对原始数据做升序排序,但是图形看上去是降序(从上往下)?那是因为水平条形图的y轴刻度值是从下往上布置的,所以条形图从下往上是满足升序的。
(2)堆叠条形图
正如前文所介绍的,不管是垂直条形图还是水平条形图,都只是反映单个离散变量的统计图形,如果想通过条形图传递两个离散变量的信息该如何做到?相信读者一定见过堆叠条形图,该类型条形图的横坐标代表一个维度的离散变量,堆叠起来的“块”代表了另一个维度的离散变量。这样的条形图,最大的优点是可以方便比较累积和,那这种条形图该如何通过Python绘制呢?这里以2017年四个季度的产业值为例(数据来源于中国统计局),绘制堆叠条形图,详细代码如下:


如上就是一个典型的堆叠条形图,虽然绘图的代码有些偏长,但是其思想还是比较简单的,就是分别针对三种产业的产值绘制三次条形图。需要注意的是,第二产业的条形图是在第一产业的基础上做了叠加,故需要将bottom参数设置为Industry1;而第三产业的条形图又是叠加在第一和第二产业之上,所以需要将bottom参数设置为Industry1+ Industry2。
读者可能疑惑,通过条件判断将三种产业的值(Industry1、Industry2、Industry3)分别取出来后,为什么还要重新设置行索引?那是因为各季度下每一种产业值前的行索引都不相同,这就导致无法进行Industry1+ Industry2的和计算(读者不妨试试不改变序列Industry1和Industry2的行索引的后果)。
(3)水平交错条形图
堆叠条形图可以包含两个离散变量的信息,而且可以比较各季度整体产值的高低水平,但是其缺点是不易区分“块”之间的差异,例如二、三季度的第三产业值差异就不是很明显,区分高低就相对困难。而交错条形图恰好就可以解决这个问题,该类型的条形图就是将堆叠的“块”水平排开,如想绘制这样的条形图,可以参考下方代码(数据来源于胡润财富榜,反映的是5个城市亿万资产超高净值家庭数):

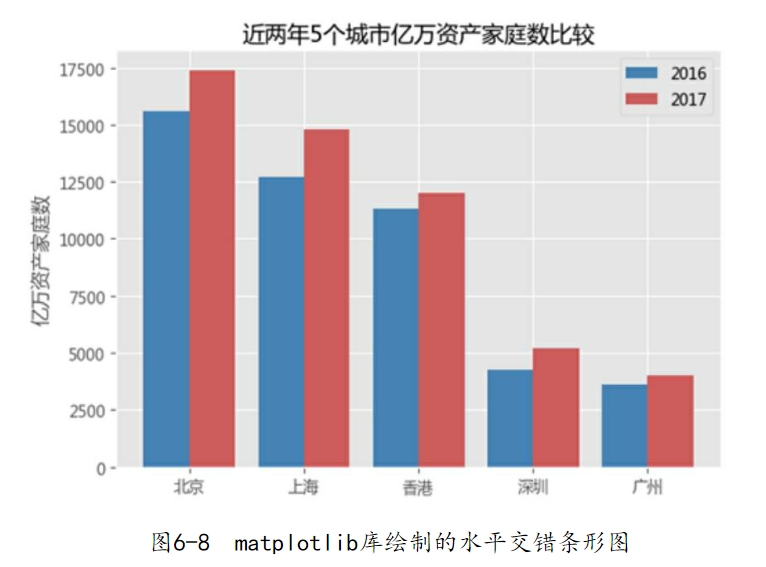
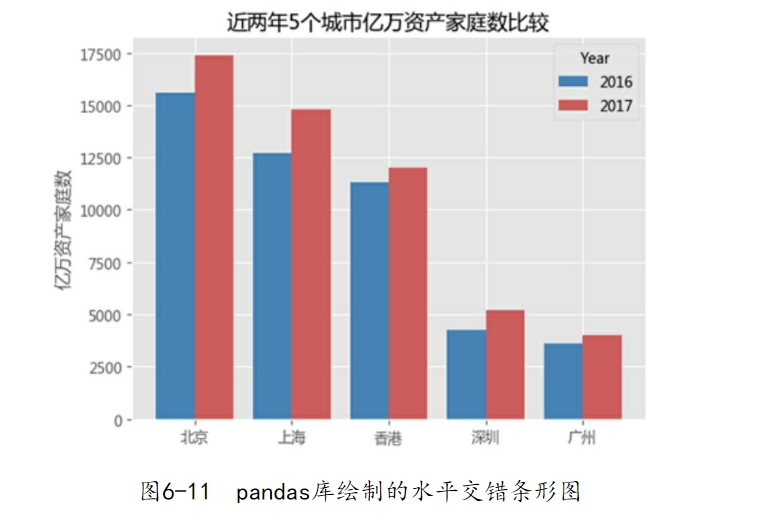
图6-8反映的是2016年和2017年5大城市亿万资产家庭数的条形图,可以很好地比较不同年份下的差异。例如,这5个城市中,2017年的亿万资产家庭数较2016年都有所增加。
但是对于这种数据,就不适合使用堆叠条形图,因为堆叠条形图可以反映总计的概念。如果将2016年和2017年亿万资产家庭数堆叠计总,就会出现问题,因为大部分家庭数在这两年内都被重复统计在胡润财富榜中,计算出来的总和会被扩大。另外,再对如上的代码做三点解释,希望能够帮助读者解去疑惑:
如上的水平交错条形图,其实质就是使用两次bar函数,所不同的是,第二次bar函数使得条形图往右偏了0.4个单位(left=np.arange(len(Cities))+bar_width),进而形成水平交错条形图的效果。
每一个bar函数,都必须控制条形图的宽度(width=bar_width),否则会导致条形图的重叠。
如果利用bar函数的tick_label参数添加条形图x轴上的刻度标签,会发现标签并不是居中对齐在两个条形图之间,为了克服这个问题,使用了pyplot子模块中的xticks函数,并且使刻度标签的位置向右移0.2个单位。
2.pandas模块
通过pandas模块绘制条形图仍然使用plot方法,该“方法”的语法和参数含义在前文已经详细介绍过,但是plot方法存在一点瑕疵,那就是无法绘制堆叠条形图。下面通过该模块的plot方法绘制单个离散变量的垂直条形图或水平条形图以及两个离散变量的水平交错条形图,代码如下:

只要掌握matplotlib模块绘制单个离散变量的条形图方法,就可以套用到pandas模块中的plot方法,两者是相通的。读者可以尝试plot方法绘制水平条形图,这里就不再给出参考代码了。接下来使用plot方法绘制含两个离散变量的水平交错条形图,具体代码如下:

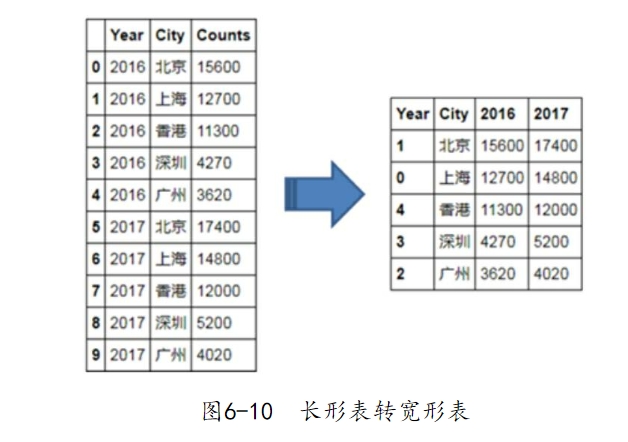
如上代码所示,应用plot方法绘制水平交错条形图,必须更改原始数据集的形状,即将两个离散型变量的水平值分别布置到行与列中(代码中采用透视表的方法实现),最终形成的表格变换如图6-10所示。
针对变换后的数据,可以使用plot方法实现水平交错条形图的绘制,从代码量来看,要比使用matplotlib模块简短一些,得到的条形图如图6-11所示。
3.seaborn模块绘制条形图
seaborn模块是一款专门用于绘制统计图形的利器,通过该模块写出来的代码也是非常通俗易懂的。该模块并不在Anoconda集成工具中,故需要读者另行下载。下面就简单介绍一下如何通过该模块完成条形图的绘制(同样无法绘制堆叠条形图)。

如上代码就是通过seaborn模块中的barplot函数实现单个离散变量的条形图。除此之外,seaborn模块中的barplot函数还可以绘制两个离散变量的水平交错条形图,所以有必要介绍一下该函数的用法及重要参数含义:
sns.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,ci=95, n_boot=1000, orient=None, color=None, palette=None,saturation=0.75, errcolor='.26', errwidth=None, dodge=True, ax=None, **kwargs)

为了说明如上函数中的参数,这里以泰坦尼克号数据集为例,绘制水平交错条形图,代码如下:

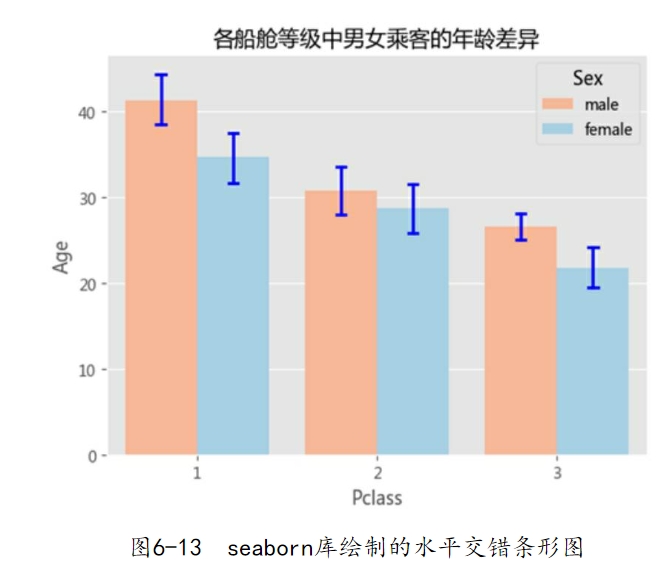
如图6-13所示,绘制的每一个条形图中都含有一条竖线,该竖线就是条形图的误差棒,即各组别下年龄的标准差大小。从图6-13可知,三等舱的男性乘客年龄是最为接近的,因为标准差最小。
需要注意的是,数据集Titanic并非汇总好的数据,是不可以直接应用到matplotlib模块中的bar函数与pandas模块中的plot方法。如需使用,必须先对数据集进行分组聚合,关于分组聚合的内容已经在第5章中介绍过,读者可以前去了解。






