我们需要用数字表示观测值(文本),以便与机器学习算法一起使用。图 1-2 给出了一个可视化的描述。

表示文本的一种简单方法是用数字向量表示。有无数种方法可以执行这种映射/表示。事实上,本书的大部分内容都致力于从数据中学习此类任务表示。然而,我们从基于启发式的一些简单的基于计数的表示开始。虽然简单,但是它们非常强大,或者可以作为更丰富的表示学习的起点。所有这些基于计数的表示都是从一个固定维数的向量开始的。
单热表示
顾名思义,单热表示从一个零向量开始,如果单词出现在句子或文档中,则将向量中的相应条目设置为 1。考虑下面两句话。
Time flies like an arrow.Fruit flies like a banana.
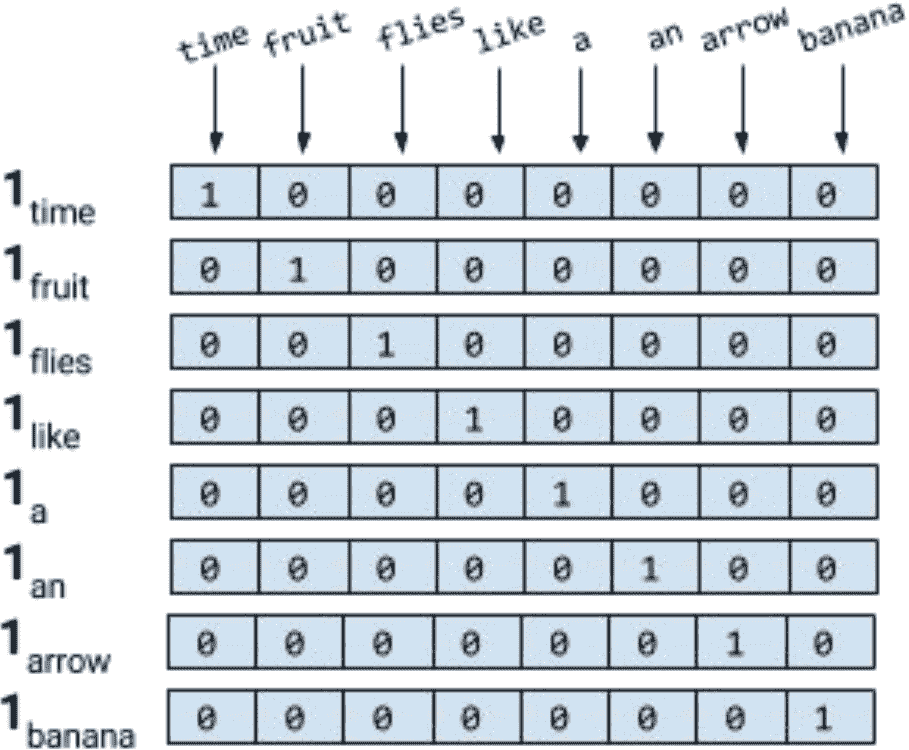
对句子进行标记,忽略标点符号,并将所有的单词都用小写字母表示,就会得到一个大小为 8 的词汇表:{time, fruit, flies, like, a, an, arrow, banana}。所以,我们可以用一个八维的单热向量来表示每个单词。在本书中,我们使用1[w]表示标记/单词w的单热表示。
对于短语、句子或文档,压缩的单热表示仅仅是其组成词的逻辑或的单热表示。使用图 1-3 所示的编码,短语like a banana的单热表示将是一个3×8矩阵,其中的列是 8 维的单热向量。通常还会看到“折叠”或二进制编码,其中文本/短语由词汇表长度的向量表示,用 0 和 1 表示单词的缺失或存在。like a banana的二进制编码是:[0,0,0,1,1,0,0,1]。
注意:在这一点上,如果你觉得我们把flies的两种不同的意思(或感觉)搞混了,恭喜你,聪明的读者!语言充满了歧义,但是我们仍然可以通过极其简化的假设来构建有用的解决方案。学习特定于意义的表示是可能的,但是我们现在做得有些超前了。
尽管对于本书中的输入,我们很少使用除了单热表示之外的其他表示,但是由于 NLP 中受欢迎、历史原因和完成目的,我们现在介绍术语频率(TF)和术语频率反转文档频率(TF-idf)表示。这些表示在信息检索(IR)中有着悠久的历史,甚至在今天的生产 NLP 系统中也得到了广泛的应用。(翻译有不足)
TF 表示
短语、句子或文档的 TF 表示仅仅是构成词的单热的总和。为了继续我们愚蠢的示例,使用前面提到的单热编码,Fruit flies like time flies a fruit这句话具有以下 TF 表示:[1,2,2,1,1,1,0,0]。注意,每个条目是句子(语料库)中出现相应单词的次数的计数。我们用 TF(w)表示一个单词的 TF。
示例 1-1:使用 sklearn 生成“塌陷的”单热或二进制表示
from sklearn.feature_extraction.text import CountVectorizerimport seaborn as snscorpus = ['Time flies flies like an arrow.','Fruit flies like a banana.']one_hot_vectorizer = CountVectorizer(binary=True)one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()sns.heatmap(one_hot, annot=True,cbar=False, xticklabels=vocab,yticklabels=['Sentence 1', 'Sentence 2'])
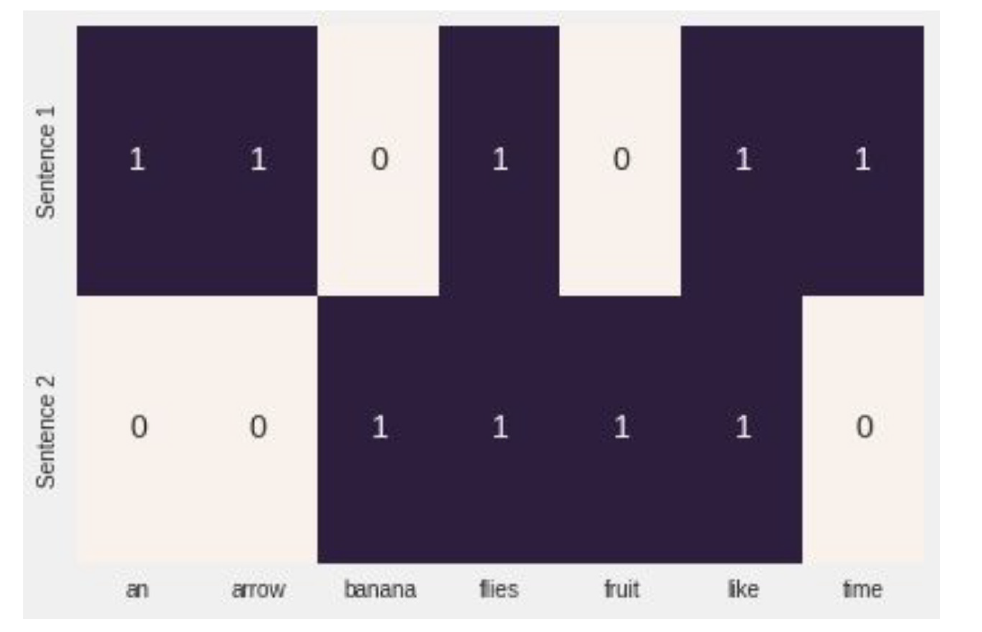
折叠的单热是一个向量中有多个 1 的单热
TF-IDF 表示
考虑一组专利文件。您可能希望它们中的大多数都有诸如claim、system、method、procedure等单词,并且经常重复多次。TF 表示对更频繁的单词进行加权。然而,像claim这样的常用词并不能增加我们对具体专利的理解。相反,如果tetrafluoroethylene这样罕见的词出现的频率较低,但很可能表明专利文件的性质,我们希望在我们的表述中赋予它更大的权重。反文档频率(IDF)是一种启发式算法,可以精确地做到这一点。
IDF 表示惩罚常见的符号,并奖励向量表示中的罕见符号。 符号w的IDF(w)对语料库的定义为
其中n[w]是包含单词w的文档数量,N是文档总数。TF-IDF 分数就是TF(w) * IDF(w)的乘积。首先,请注意在所有文档(例如,n[w] = N), IDF(w)为 0, TF-IDF 得分为 0,完全惩罚了这一项。其次,如果一个术语很少出现(可能只出现在一个文档中),那么 IDF 就是log n的最大值。
示例 1-2:使用 sklearn 生产 TF-IDF 表示
from sklearn.feature_extraction.text import TfidfVectorizerimport seaborn as snstfidf_vectorizer = TfidfVectorizer()tfidf = tfidf_vectorizer.fit_transform(corpus).toarray()sns.heatmap(tfidf, annot=True, cbar=False, xticklabels=vocab,yticklabels= ['Sentence 1', 'Sentence 2'])
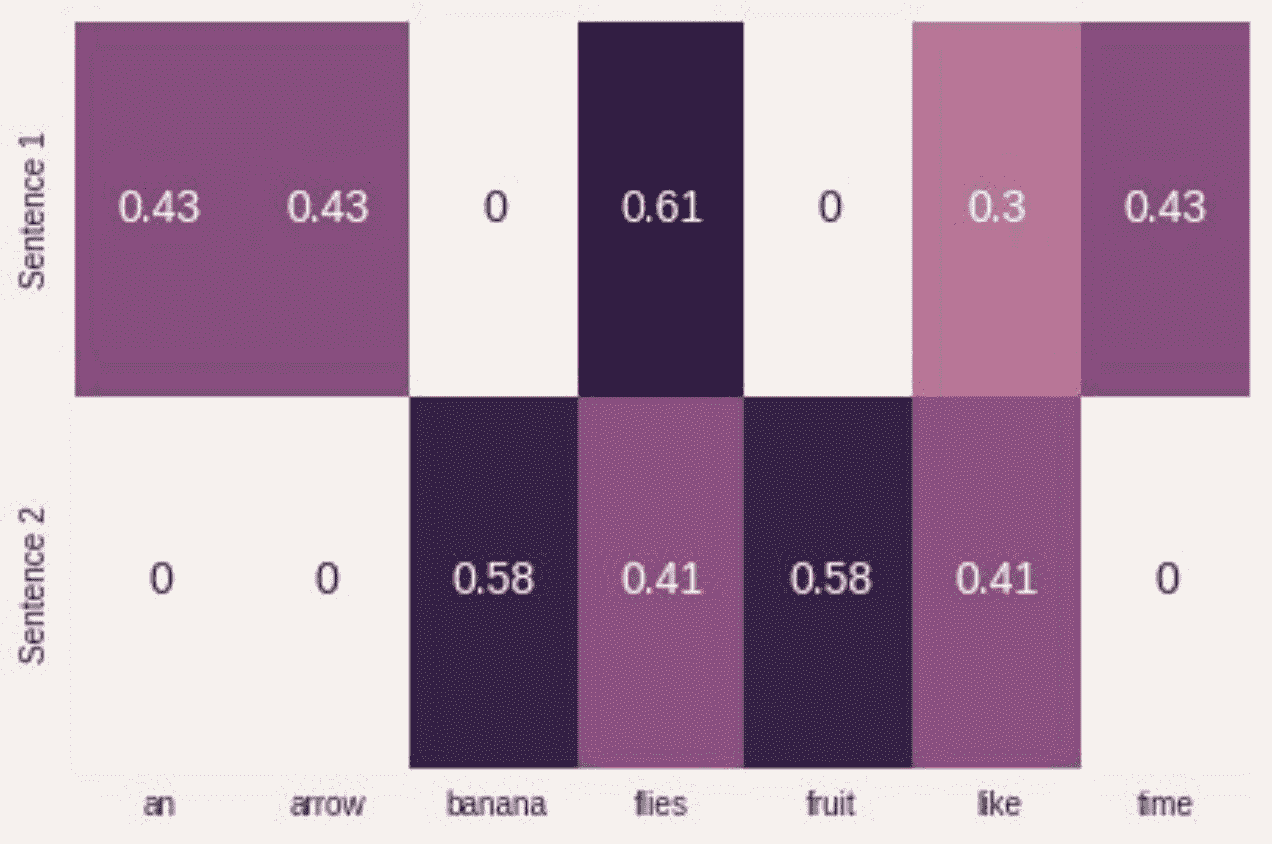
在深度学习中,很少看到使用像 TF-IDF 这样的启发式表示对输入进行编码,因为目标是学习一种表示。通常,我们从一个使用整数索引的单热编码和一个特殊的“嵌入查找”层开始构建神经网络的输入。在后面的章节中,我们将给出几个这样做的例子。
目标编码
正如“监督学习范式”所指出的,目标变量的确切性质取决于所解决的 NLP 任务。例如,在机器翻译、摘要和回答问题的情况下,目标也是文本,并使用前面描述的单热编码方法进行编码。
许多 NLP 任务实际上使用分类标签,其中模型必须预测一组固定标签中的一个。对此进行编码的一种常见方法是对每个标签使用惟一索引。当输出标签的数量太大时,这种简单的表示可能会出现问题。这方面的一个例子是语言建模问题,在这个问题中,任务是预测下一个单词,给定过去看到的单词。标签空间是一种语言的全部词汇,它可以很容易地增长到几十万,包括特殊字符、名称等等。我们将在后面的章节中重新讨论这个问题以及如何解决这个问题。
一些 NLP 问题涉及从给定文本中预测一个数值。例如,给定一篇英语文章,我们可能需要分配一个数字评分或可读性评分。给定一个餐馆评论片段,我们可能需要预测直到小数点后第一位的星级。给定用户的推文,我们可能需要预测用户的年龄群。有几种方法可以对数字目标进行编码,但是将目标简单地绑定到分类“容器”中(例如,“0-18”、“19-25”、“25-30”等等),并将其视为有序分类问题是一种合理的方法。 绑定可以是均匀的,也可以是非均匀的,数据驱动的。虽然关于这一点的详细讨论超出了本书的范围,但是我们提请您注意这些问题,因为在这种情况下,目标编码会显著影响性能,我们鼓励您参阅 Dougherty 等人(1995)及其引用。
计算图
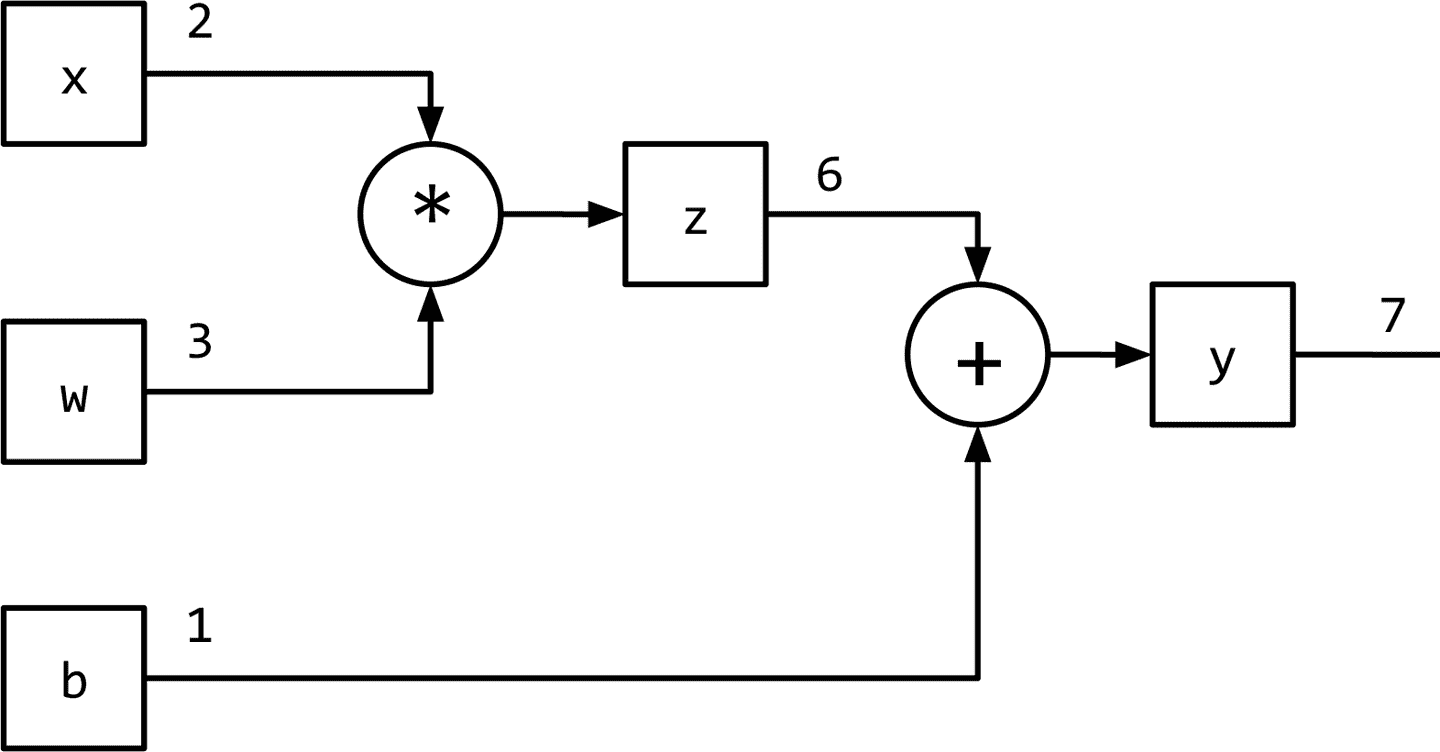
图 1-1 将监督学习(训练)范式概括为数据流架构,模型(数学表达式)对输入进行转换以获得预测,损失函数(另一个表达式)提供反馈信号来调整模型的参数。利用计算图数据结构可以方便地实现该数据流。从技术上讲,计算图是对数学表达式建模的抽象。在深度学习的上下文中,计算图的实现(如 Theano、TensorFlow 和 PyTorch)进行了额外的记录(bookkeeping),以实现在监督学习范式中训练期间获取参数梯度所需的自动微分。我们将在“PyTorch 基础知识”中进一步探讨这一点。推理(或预测)就是简单的表达式求值(计算图上的正向流)。让我们看看计算图如何建模表达式。考虑表达式:y=wx+b
这可以写成两个子表达式z = wx和y = z + b,然后我们可以用一个有向无环图(DAG)表示原始表达式,其中的节点是乘法和加法等数学运算。操作的输入是节点的传入边,操作的输出是传出边。因此,对于表达式y = wx + b,计算图如图 1-6 所示。在下一节中,我们将看到 PyTorch 如何让我们以一种直观的方式创建计算图形,以及它如何让我们计算梯度,而无需考虑任何记录(bookkeeping)。